自我介绍
你好,我叫李飞翔,目前研三在读。本科毕业于金陵科技学院,专业是软件工程专业。研究生就读于太原理工大学,专业是计算机科学与技术。研究生阶段的领域是计算机视觉,主要方向是半监督医学图像分割。研究生阶段主要的工作一下三项,第一个就是参与导师的省基金和国家基金的撰写,负责其中的一个章节还有整体的汇总,主要涉及的内容是多模态和自监督对比学习。第二个就是国赛的项目,用到的技术栈有vue3+Springboot+python+django+pytorch。研究课题是图像隐写,针对目前隐写模型不支持中文,隐写容量小,隐写质量不高,模糊等三个问题,提出了基于纹理的大容量隐写模型。提出一种Pre-RS预处理模块对压缩后的信息进行RS纠错编码及重排实现对中文的支持,第二个引入CES算法对文本内容进行压缩处理,实现对大容量文本信息的嵌入。第三个提出了噪声-补偿模块来减少噪声对模型的影响。使用阿里云的云效结合flask快速部署成docker项目,对外开放接口。使用vue写前台页面,srpingboot负责后台编写,用户的登录注册,调用docker服务。做成一个落地的应用。
第三个项目,我是拿来练手的项目,做的是在线oj项目。技术栈主要是springcloud,redis,mysql以及rabbitmq。项目就是和leetcode类似。主要的是刷题和比赛的功能。主要有用户模块,主要内容就是登录,注册,做题,题目信息查看。题目模块,提供题目的增删改查管理、题目提交功能。还有判题模块提供判题功能,调用代码沙箱并比对判题结果,代码沙箱,实现编译执行代码,返回输出结果。通过docker技术进行系统级别的隔离,实现执行的安全性。
项目面经
想要融合的项目
一个资源管理
https://www.bilibili.com/video/BV18A411L7UX 讲课视频 49小时 每天8小时。2周内完成
Han-YLun/SaaS_IHRM: Saas Inteintelligence Human Resouce Managment backend (github.com)
Han-YLun/SaaS_IHRM_Vue: Saas Inteintelligence Human Resouce Managment front end (github.com)
计划做一个太理的在线交流平台
二手交易,
https://www.bilibili.com/video/BV1cr4y1671t
交友,表白墙。
https://www.bilibili.com/video/BV1vh4y1c7E7 在线考试
webrtc 技术栈
WebRTC原理与开发实战【已完结】_哔哩哔哩_bilibili
即时通讯 视频通话 netty webrtc websocket springboot uniapp_哔哩哔哩_bilibili
音视频QoS技术:快速入门WebRTC带宽估计/拥塞控制GCC技术_哔哩哔哩_bilibili
直播技术
galaxy-s10/billd-live-server: 基于Nodejs + Koa2 + Typescript搭建的billd-live后端 (github.com)
黑马点评
huyi612/hm-dianping (gitee.com)
个人博客
https://www.bilibili.com/video/BV1hq4y1F7zk
后端:https://github.com/caoyingjunz/pixiu 前端:https://github.com/gopixiu-io/dashboard
我的项目有哪些亮点
代码沙箱:
- 技术难度:较高。涉及到系统级别的操作和安全性控制。
- 解决方案:利用Docker进行代码执行环境的隔离,并且需要确保代码的执行不会影响到宿主机的安全性。
支持不同语言:
2.限制单个用户的提交频率,通过IP限流实现 3.使用事务确保题目提交的完整性:添加题目到题目提交表、更新题目提交数+1、将提交题目ID放入消息队列
如何保证redis和mysql数据的一致性,使用的是,redis的
为什么使用docker? 怎么保证docker代码沙箱执行的安全性的
1.超时控制:在向容器发送执行命令时,指定超时参数,超时自动中断
2.资源限制:创建容器实例时,通过HostConfig 指定分配的最大内存和CPU占用
3.网络限制:创建容器实例时,通过withNetworkDisabled方法禁用网络
4.权限管理:通过seccomp 或者Java安全管理器,限制用户代码允许的操作和调用
你是如何通过自定义Gateway 的GlobalFilter来保护接口的,请介绍具体实现过程?
背景:为防止服务内部相互调用的接口被外部系统访问,需要在网关集中定义接口保护逻辑。 具体实现: GlobalFilter是Spring Cloud Gateway提供的全局请求拦截接口,我编写了一个类实现了该接口,重写了其filter 方法,并在该方法中编写了接保护逻辑。 接口保护逻辑:获取到当前请求的目标路径,使用AntPathMatcher判断该路径是否包含inner,如果包含的话,设置响应码为403 FORBIDDEN并返回;不包含的话,放行请求继续执行。 值得一提的是,为了让上述逻辑优先生效,我让这个类实现了Ordered 接口并且将getOrder方法的返回值设置为О(最高优先级),能够做到尽早拦截违规请求,避免不必要的开销。
Java原生代码沙箱和Docker 代码沙箱这两种实现方式的核心业务流程是相同的,都需要经历以下几个步骤:
- 把用户的代码保存为文件
- 编译代码,得到class文件
- 执行Java 代码
- 收集整理输出结果
- 文件清理,释放空间
- 错误处理,提升程序健壮性
什么是Docker?为什么要在项目中用到 Docker?以及你在项目中是如何使用Docker的?前半句背诵类题目,后半句主观回答
Docker是一种容器化技术,它允许开发者将应用程序及其所有依赖项打包到一个独立的容器中,包括操作系统、 库、运行时环境等。这个容器可以在任何支持Docker 的平台上运行,确保应用程序在不同环境中具有一致的行为。 在本项目中使用Docker主要是为了保证代码沙箱服务执行用户代码的安全性,防止影响宿主机。 我首先在Linux虚拟机内安装了Docker,然后用Docker命令行跑通了一次从拉取镜像、执行容器再到删除容器的完整流程。在代码沙箱项目中,使用Docker Java库来操作Docker,包括Docker容器的创建、连接Docker容器执行命令、获取 Docker容器的日志和输出、获取 Docker容器的内存占用等。
请介绍一下使用Redis分布式 Session实现用户登录的原理?
用户登录过程:用户登录成功后,在后端生成一个唯一的Session标识(通常是一个SessionIlD),用于标识 该用户的登录状态。
用户信息存储:用户信息包括用户id、昵称、角色等,封装到一个Java对象中,然后将其存储到Redis.
生成SessionID:生成一个唯一的SessionID,通常是一个随机字符串,用于关联用户和Session信息。
Session信息存储到Redis:存储时使用SessionIlD作为键,将用户信息序列化为字符串或其他适当的格式作 为值,存储的时效性通常由Session的过期时间决定。
SessionID返回给前端:将生成的SessionID返回给前端,通常通过HTTP的Cookie或其他方式返回(这 —步由框架帮你做了)
后续请求:用户的后续请求会携带SessionIlD,后端通过SessionlD 从Redis 中获取用户信息,以便进行用 户身份验证。
Session过期管理:一定要设置Session的过期时间,确保Session在用户不活动的一段时间后自动失效, 以释放资源并提高安全性。
谈谈对金融科技岗的看法
首先金融的前景肯定是不错的,无论经济如何,金融都将存在且发挥重要作用;其次,金融是为实体经济服务的,金融一直以来都是实体经济的润滑剂,完全脱离了实体经济的金融不可取.
金融科技岗位,通常简称为“Fintech”,是近年来金融行业中最具创新性和发展潜力的领域之一。我认为金融科技岗位代表了金融与技术的完美结合,它不仅正在重塑金融行业的传统业务模式,而且为消费者和企业提供了更高效、便捷和个性化的金融服务。
首先,金融科技的出现解决了传统金融服务中的许多痛点。例如,通过数字化和自动化技术,金融科技公司能够提供更快速的贷款审批、更低的交易成本和更便捷的支付体验。此外,利用大数据和人工智能技术,金融科技公司可以更准确地评估风险,为客户提供更精确的信贷和投资建议。
其次,金融科技为金融行业带来了巨大的创新机会。传统的金融机构,如银行和保险公司,正在与金融科技公司合作,共同开发新的产品和服务,以满足市场的变化需求。同时,金融科技也为创业者提供了广阔的发展空间,许多初创公司已经在这个领域取得了显著的成功。
最后,我认为金融科技岗位对于专业人才提出了更高的要求。这不仅需要具备深厚的金融知识,还需要掌握先进的技术能力,如编程、数据分析和机器学习。这为我等年轻人提供了一个展现自己才华和创新思维的绝佳平台。
总的来说,我对金融科技岗位充满了期待和热情,我相信这是一个充满机会和挑战的领域,也是我未来职业发展的理想选择。
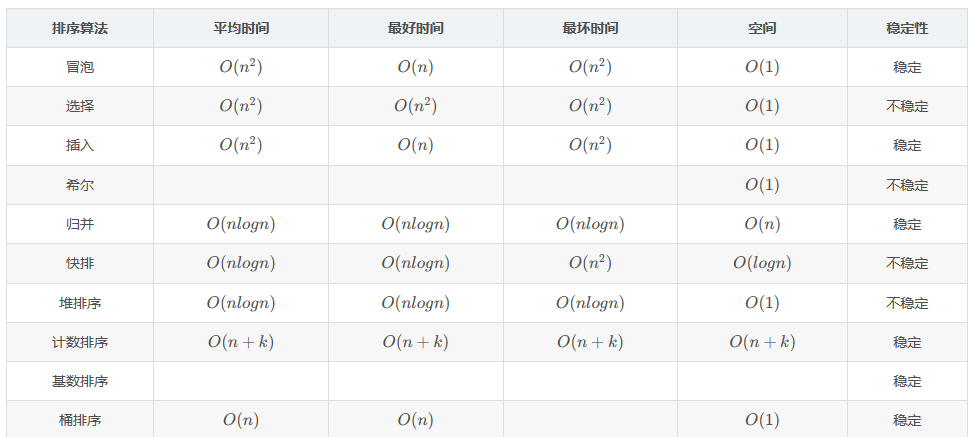
手撕
- 链表是否有环
- 快排,堆排序
- 找众数
- 层次遍历
- 链表输出倒数第k个节点
- 二叉搜索树转换为双向有序链表
- 翻转链表2
- 最长递增序列
- 找到数组的播放
- LRU
- 两个ArrayList有一部分相同的数据,怎么求交集
- 返回二叉树最宽的一列
- 二叉树的右视图
1. 计算机网络
软件设计七大原则
1.开闭原则,对扩展开放,对修改关闭
2.依赖倒置原则,高层模块不应该依赖低层模块,二者都应该依赖其抽象
3.单一职责原则,一个类负责一个职责
4.接口隔离原则,用多个专门的接口,而不使用单一的总接口
5.迪米特法则,一个对象应该对其他对象保持最少的了解
6.里斯替换原则,将父类对象替换为子类对象时,程序没有影响
7.合成复用原则,尽量使用对象组合,尽量不用继承
HTTPS
什么是跨域?常见的解决方案?
跨域:浏览器对于javascript的同源策略的限制 。同源策略的目的,是为了保证用户信息的安全,防止恶意的网站窃取数据。所谓的同源是指,域名、协议、端口均为相同。
因为跨域问题是浏览器对于ajax请求的一种安全限制:一个页面发起的ajax请求,只能是与当前页域名相同的路径,这能有效的阻止跨站攻击。
解决方案:1. jsonp跨域其实也是JavaScript设计模式中的一种代理模式。2. document.domain + iframe 跨域跨域资源共享 CORS。3. window.name + iframe 跨域 4. location.hash + iframe 跨域5. postMessage跨域 6. CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。 它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
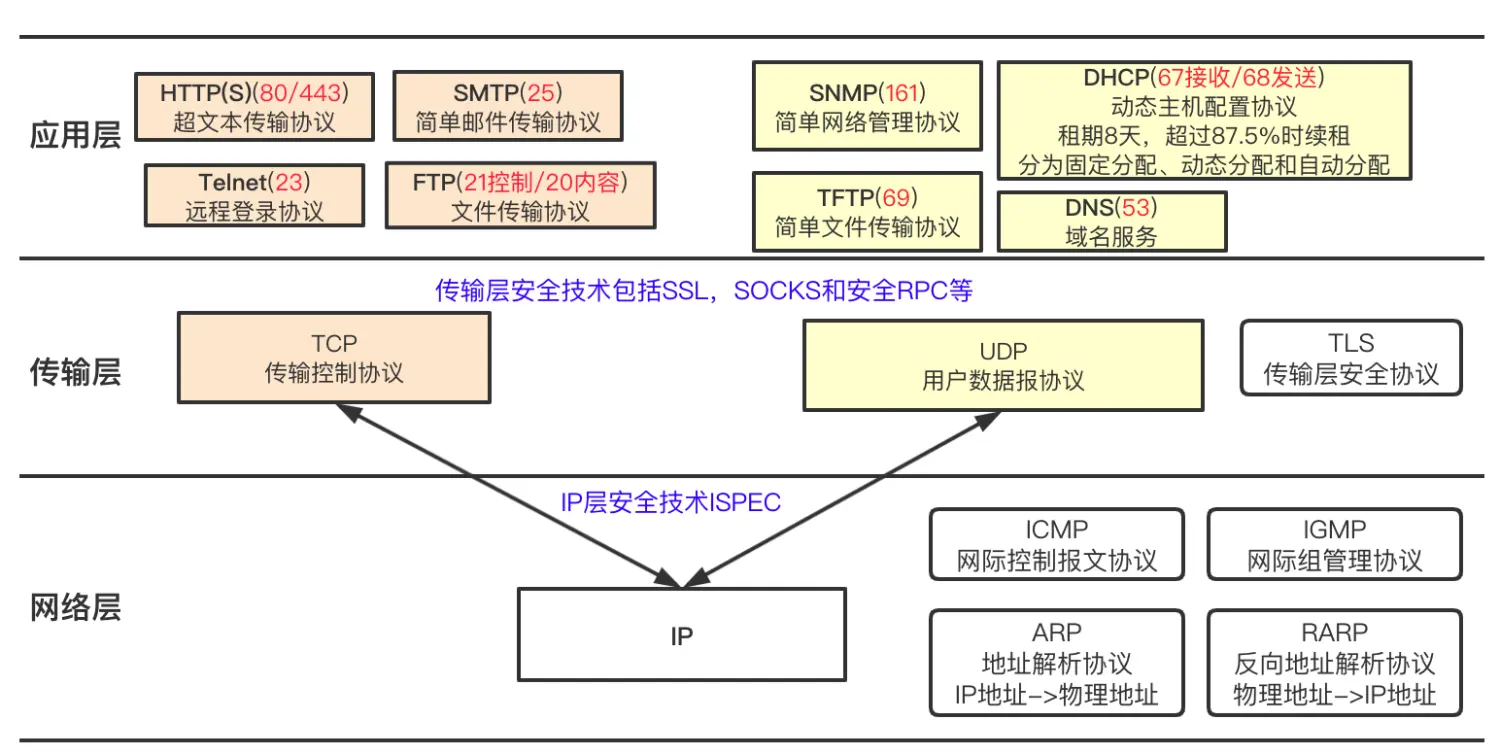
http协议和rpc协议之间的区别
http是网页端和服务端之间的一个协议,rpc呢是一个远程调用协议,是定位在实现不同计算机应用之间的一个通信。屏蔽了通信底层的复杂度,让开发者能够像调用本地服务一样,完成远程服务的一个调用。
http协议呢,它是一个已经实现并且成熟的应用层协议,它定义了通信报文的一些格式,比如像request body和header。
rpc只是一种通信协议的一个规范,它并没有具体的实现。只有按照rpc通信协议规范去实现的通信框架,才是协议的真正具体的实现。
TCP为什么设计三次握手
TCP协议是一种可靠的,基于字节流的,面向连接的传输层协议。
TCP使用三次握手的方式,来实现连接的一个建立。
就是通信双方一共需要发送三次请求,才能确保一个可靠连接的建立。Syn(建立连接) 、Ack(确认标记)、fin(终止标记)
- 客户端向服务端发送链接请求并携带同步序列号SYN
- 服务端收到请求后,发送SYN和ACK,SYN是服务端的一个同步序列号。ACK是对前面的一个客户端请求的一个确认。表示告诉客户端,我收到你的请求了
- 客户端收到服务端的请求后,再次发送ACK.表示客户端对服务端链接的确认,表示告诉服务端我收到你的请求,
四次挥手
TCP是可靠性通信协议,所以TCP协议的通信双方必须要维护一个序列号,去标记已经发送出去的数据包,哪些是已经被对方签收的,而三次握手就是通信双方互相通告序列号的起始值,为了确保这个序列号被收到,所以双方都需要有一个确认的操作。
TCP协议需要再一个不可靠的网络环境下实现可靠的数据传输,意味着通信双方必须要通过某种手段来实现一个可靠的数据传输通道,而三次通信是建立这样一个通道的最小值。
防止历史的重复链接初始化造成的混乱问题。比如在网络比较差的情况下,客户端连续多次发送连接的请求,假设只有两次握手,那么服务端只能选择接受或者拒绝这个请求,但是服务端不知道这个请求是不是之前网络堵塞而国企的请求。也就是说服务端不知道当前客户端的链接是是有效还是无效
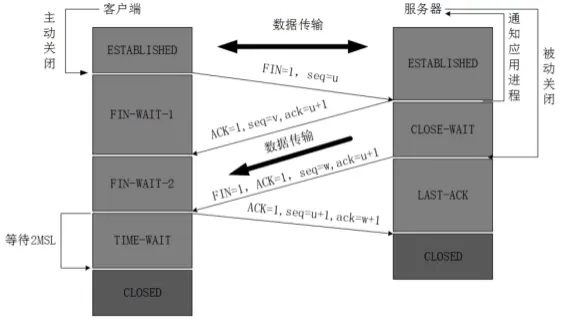
白话文翻译: 第一次挥手:客户端向服务端发送一个释放连接通知; 第二次挥手:服务端接受到释放通知之后,告诉给客户端说等待一下,因为可能存在有其他的数据没有发送完毕,等待数据全部传输完毕之后就开始 关闭连接; 第三次挥手:服务器端所有的数据发送完毕之后,就告诉客户端说现在可以释放连接了。 第四次挥手:客户端确认是最终释放连接通知,ok 就开始 就向服务区端发送我们可以开始关闭连接啦;
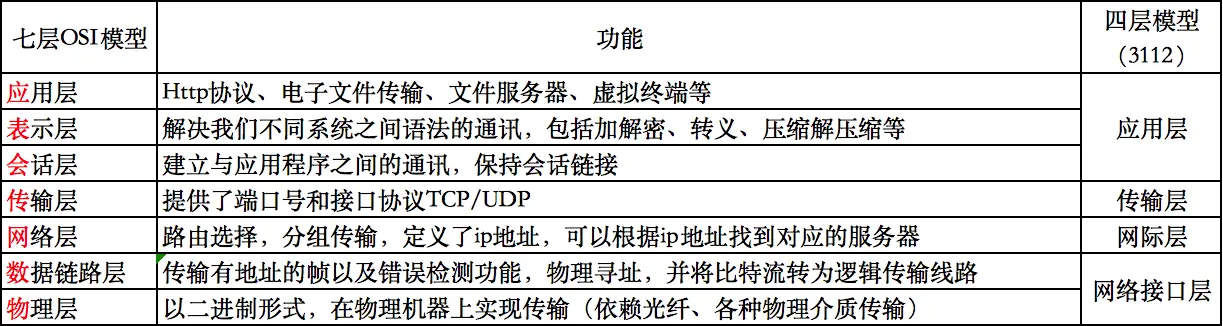
七层IOS模型
TCP和UDP区别
TCP:可靠的,面相连接的,字节流服务的,首部开销20个字节。具有差错校验和重传,流量控制,拥塞控制(多通道)等功能,适用于数据量比较少,且对可靠性要求搞定场景
UDP 不可靠,无连接,面向报文,首部开销8个字节
数据量大,对可靠性要求不是很高,但是要求速度快的场合
https和http的区别?
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
TCP确保传输可靠性的方式
- 校验和
- 序列号/确认应答
- 超时重传
- 连接管理
- 流量控制(滑动窗口控制)
- 拥塞控制
校验和:
TCP校验和是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则TCP段会被直接丢弃,重新发送。
TCP在计算检验和时,会在TCP首部加上一个12字节的伪首部。检验和总共计算3部分:TCP伪首部,TCP首部、TCP数据。
超时重传
在进行TCP传输时,由于确认应答与序列号机制,也就是说发送方发送一部分数据后,都会等待接收方发送的ACK报文,并解析ACK报文,判断数据是否传输成功。如果发送方发送完数据后,迟迟没有等到接收方的ACK报文,这该怎么办呢?而没有收到ACK报文的原因可能是什么呢?
首先,发送方没有介绍到响应的ACK报文原因可能有两点:
- 数据在传输过程中由于网络原因等直接全体丢包,接收方根本没有接收到。
- 接收方接收到了响应的数据,但是发送的ACK报文响应却由于网络原因丢包了。
连接管理
连接管理就是三次握手与四次挥手的过程,在前面详细讲过这个过程,这里不再赘述。保证可靠的连接,是保证可靠性的前提。
流量控制(滑动窗口控制)
接收端在接收到数据后,对其进行处理。如果发送端的发送速度太快,导致接收端的结束缓冲区很快的填充满了。此时如果发送端仍旧发送数据,那么接下来发送的数据都会丢包,继而导致丢包的一系列连锁反应,超时重传呀什么的。而TCP根据接收端对数据的处理能力,决定发送端的发送速度,这个机制就是流量控制。
拥塞控制
TCP传输的过程中,发送端开始发送数据的时候,如果刚开始就发送大量的数据,那么就可能造成一些问题。网络可能在开始的时候就很拥堵,如果给网络中在扔出大量数据,那么这个拥堵就会加剧。拥堵的加剧就会产生大量的丢包,以及大量的超时重传,严重影响传输。
所以就产生了拥塞控制这个概念,它的主要机制: 慢开始( slow-start )、拥塞避免( congestion avoidance )、快重传( fast retransmit )和快恢复( fast recovery )。
http状态码
1xx 表示请求已被接受,但需要后续处理。100(Continue)客户端应继续发送请求。
2xx 请求已成功被服务器接收、理解、并接受。
- 200(OK)请求已成功,请求所希望的响应头或数据体将随此响应返回。
- 3xx 这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向, 重定向目标在本次响应的
Location头字段中指明。
301(Moved Permanently)
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果该请求不是GET/HEAD, 浏览器通常会要求用户确认重定向。
301通常用于网站迁移时,服务器对旧的URL进行301重定向到新的URL。这样搜索引擎可以正确地更新原有的页面排名等信息。
- 4xx 这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。 除非响应的是一个HEAD请求,否则服务器就应该返回一个解释当前错误状况的实体。
400(Bad Request)
由于包含语法错误,当前请求无法被服务器理解。400通常在服务器端表单验证失败时返回。
5xx 这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。 并且响应消息体中应当给出理由,除非是HEAD请求。
500(Internal Server Error) 通常是代码出错,后台Bug。一般的Web服务器通常会给出抛出异常的调用堆栈。 然而多数服务器即使在生产环境也会打出调用堆栈,这显然是不安全的。
502(Bad Gateway)作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。如果你在用HTTP代理来翻墙,或者你配置了nginx来反向代理你的应用,你可能会常常看到它。
http1和http2区别
1.新的二进制格式:HTTP2采用二进制格式而HTTP1使用文本格式。
2.多路复用:HTTP2是完全多复用的,而非有序并阻塞的,只需一个连接即可实现并行。HTTP1一个连接只能发送一个请求。
3.首部压缩:HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
4.服务器推送:HTTP2在客户端请求资源的时候,会把相关的资源一起发送给客户端,而不需要客户端再次发起请求获取资源。
二、什么是HTTP2.0
HTTP/2(超文本传输协议第2版,最初命名为HTTP 2.0),是HTTP协议的的第二个主要版本,使用于万维网。HTTP/2是HTTP协议自1999年HTTP 1.1发布后的首个更新,主要基于SPDY协议(是Google开发的基于TCP的应用层协议,用以最小化网络延迟,提升网络速度,优化用户的网络使用体验)。
三、为什么需要头部压缩?
HTTP协议是不带有状态的,每次请求头部都会附上所有的信息,而且很多的信息都是重复的,这会浪费很多宽带也会影响速度,所以HTTP2对头部进行了压缩,一方面使用gzip或compress进行头部压缩,另一方面,客户端和服务器会同时维护同一张头信息表,所有的字段都会存入这张表中,生成一个索引号,以后就不需要再发送同样的字段了,只发送索引号,提示了速度。
用户态和内核态区别
内核态(Kernel Mode):运行操作系统程序,操作硬件
用户态(User Mode):运行用户程序
内核态与用户态是操作系统的两种运行级别,当程序运行在3级特权级上时,就可以称之为运行在用户态。因为这是最低特权级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态;
当程序运行在0级特权级上时,就可以称之为运行在内核态。
运行在用户态下的程序不能直接访问操作系统内核数据结构和程序。当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态(比如操作硬件)。
这两种状态的主要差别是
- 处于用户态执行时,进程所能访问的内存空间和对象受到限制,其所处于占有的处理器是可被抢占的
- 处于内核态执行时,则能访问所有的内存空间和对象,且所占有的处理器是不允许被抢占的。
以下几种情况会导致用户态到内核态的切换
- 系统调用:用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作
- 异常:当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
- 外围设备的中断:当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,
加密算法
常见的对称加密算法有 AES、SM4、ChaCha20、3DES、Salsa20、DES、Blowfish、IDEA、RC5、RC6、Camellia。目前国际主流的对称加密算法是AES,国内主推的则是国标的SM4。
AES块加密的基本逻辑是:先将密钥扩展为4个一组的N轮密钥;在执行块加密时,将输入的16个字节的明文块进一步拆分为4个小块,然后利用准备好的每一轮密钥对这四个小块做N轮的加密运算。
非对称加密算法:RSA算法是目前最广泛使用的非对称加密算法之一,其安全性主要基于大质数分解难题。RSA算法中,公钥由两个参数组成:一个是模数n,另一个是公钥指数e。私钥由模数n和私钥指数d组成。RSA算法的安全性取决于密钥长度,一般需要使用较长的密钥长度以保证安全性。
椭圆曲线密码算法(ECC)ElGamal算法
DSA:既 Digital Signature Algorithm,数字签名算法,他是由美国国家标准与技术研究所(NIST)与1991年提出。和 RSA 不同的是 DSA 仅能用于数字签名,不能进行数据加密解密,其安全性和RSA相当,但其性能要比RSA快。
Socket
在 Web 开发领域,我们最常用的协议是 HTTP,HTTP 协议和 WS 协议都是基于 TCP 所做的封装,但是 HTTP 协议从一开始便被设计成请求 -> 响应的模式,所以在很长一段时间内 HTTP 都是只能从客户端发向服务端,并不具备从服务端主动推送消息的功能,这也导致在浏览器端想要做到服务器主动推送的效果只能用一些轮询和长轮询的方案来做,但因为它们并不是真正的全双工,所以在消耗资源多的同时,实时性也没理想中那么好。 既然市场有需求,那肯定也会有对应的新技术出现,WebSocket 就是这样的背景下被开发与制定出来的,并且它作为 HTML5 规范的一部分,得到了所有主流浏览器的支持,同时它还兼容了 HTTP 协议,默认使用 HTTP 的80端口和443端口,同时使用 HTTP header 进行协议升级。 和 HTTP 相比,WS 至少有以下几个优点:
- 使用的资源更少:因为它的头更小。
- 实时性更强:服务端可以通过连接主动向客户端推送消息。
- 有状态:开启链接之后可以不用每次都携带状态信息。
除了这几个优点以外,我觉得对于 WS 我们开发人员起码还要了解它的握手过程和协议帧的意义,这就像学习 TCP 的时候需要了解 TCP 头每个字节帧对应的意义一样。
WS 的操作符代表了 WS 的消息类型,它的消息类型主要有如下六种:
- 文本消息
- 二进制消息
- 分片消息(分片消息代表此消息是一个某个消息中的一部分,想想大文件分片)
- 连接关闭消息
- PING 消息
- PONG 消息(PING的回复就是PONG)
两万字详解!Netty经典32连问! - 哔哩哔哩 (bilibili.com)
2. Java
线程池的内存模型
深度优先遍历和广度优先遍历的应用场景?
延迟双删的代码
dns的处理流程
如何破坏双亲委派模型
IOC的优点
负载均衡的算法
Java中IO流分为两类,一类是字节流,一类是字符流。
- 字节流:InputStream、OutputStream
- 字符流:Reader、Writer
java创建对象的四种方式
使用new关键
使用class的newInstance()方法
javaPerson person = Person.class.newInstance();使用Constructor的newInstance()方法
javaConstructor<Person> constructor = Person.class.getConstructor(String.class, int.class); Person person = constructor.newInstance("小明", 18);使用clone()方法
javaclone = (Person) person.clone();使用反序列化的方法。通过序列化后,可以把对象存储到文件或网络中,然后再通过反序列化的方式恢复成对象。
javaObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.dat")); Person clone = (Person) ois.readObject();使用工厂模式
字节流和字符流有何区别?
- 字节流和字符流是根据处理数据类型区分的
- 字节流可以处理任何对象,包括二进制对象,而字符流只能处理字符或者字符串
- 字节流不能直接处理unicode字符(需要我们自己进行一些特殊处理),而字符流可以处理(已经帮助我们处理好了)
- 理论上任何文件都能用字节流来读取,但是当读取的数据为纯文本文件时,字节流需要额外进行一个转换工作,字符流已经帮我们做好了。所以只是处理纯文本会优先使用字符流,除此之外都推荐字节流
java各种数据结构?使用场景
list下面所有的类都是有序的,并且是可以重复的
set适合在要求去重的情况下使用,他并不能保证顺序,但是LinkedHashSet是可以保证插入时的顺序的
map适用于去重,和计算相的值出现的次数,hashmap可以去重但是不能保证顺序,可以选用LinkedHashMap去重的同时保证了key的顺序,TreeMap是可以去重的同时 按照大小进行排序
Object有哪些方法?
equals,toString,hashcode(),wait(),finalize(),
String,StringBuffer和StringBuilder区别?
StringBuffer是为了解决凭借大量字符串时产生多个中间对象而提供的类。
String是不可修改的,StringBuffer和StingBuilder类的对象内容可以修改的
StringBuffer是线程安全,StringBuilder线程不安全的.
StringBuffer每次获取toString都会直接使用缓存区的toStringCache值来构造一个字符串。而StringBuilder则每次都需要复制一次字符数组,再构造一个字符串。
进程与线程的区别?
进程是程序的执行实例。它包括程序本身、数据、资源(如文件)以及由操作系统保留的执行信息,如进程关系信息。
线程,又称为轻量级进程,是进程的一部分,拥有自己的栈并执行给定的代码片段。
进程和线程的主要区别在于它们的独立性、重量级性、以及资源的共享与否:
进程是资源分配的最小单位,线程是CPU调度的最小单位
进程和线程的主要区别在于它们的内存空间和资源共享方式、创建和管理的系统调用数量、以及它们的通信方式。进程是独立的,有自己的内存空间和资源,而线程则共享它们所在的进程的内存和资源。进程需要更多的系统调用进行创建和管理,而线程只需要一个系统调用就能创建多个。最后,进程需要使用IPC机制进行通信,而线程可以直接通信
什么是协程?
协程是一种用户态的轻量级线程,也被称为“纤程”或“绿色线程”,其本质是一种协作式多任务处理机制。与传统的线程和进程相比,协程的切换不是由操作系统控制,而是由程序员手动切换的,因此协程切换的代价要比线程切换的代价低得多。
协程和线程相比,有三个比较明显的优势。
1、减少了线程切换的成本。Java 中的线程,不管是创建还是切换,都需要较高的成本。子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。这也就是说,协程的效率比较高。
2、协程的第二大优势就是,不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
3、协程更轻量级。创建一个线程栈大概需要 1M 左右,而协程栈大概只需要几 K 或者几十 K。有优势也有劣势,因为前面的程序看起来在“上串下跳”,所以,协程看起来也没那么好控制。
为什么进程切换慢?
第一,进程只有在创建的时候才会申请内存。切换的时候不涉及内存上的变动,堆栈是一直保留在内存中的(因此内存变动并不是导致进程切换更慢的原因)。第二,(不严谨的说)每个进程有一个页表,都在内存里。通过这两个点可以看出,在创建方面,进程创建肯定是比线程创建要慢得多,线程创建无需开辟内存空间。
java怎么进行内存管理?
Java的内存管理主要由Java虚拟机(JVM)进行,并且基于垃圾收集(Garbage Collection,GC)机制,让程序员从繁重的内存管理工作中解脱出来。
JAVA的内存模型
并行和并发有什么区别?
并行:在多核cpu架构里,同一个时刻可以执行多个线程的能力。
并发:是指在同一个时刻,CPU能够处理任务的数量。操作系统是可以通过时间片的机制来提升CPU的一个并发能力的
什么是深拷贝和浅拷贝?
深拷贝和浅拷贝是用来描述对象或者对象数组引用数据类型的一个复制场景的。浅拷贝就是复制某一个对象的指针,而不复制这个对象本身,这种情况下就是两个引用指针指向被复制对象的同一块内存地址。而深拷贝就是说,完全创建一个一模一样的新的对象。新对象和老的对象之间不共享任何内存。对新对象的修改不会影响老对象的一个值。在JAVA这样子的语言里面,不管浅拷贝和深拷贝都需要实现Cloneable这样子的一个接口。并且实现clone()方法。然后我们在clone()方法里面实现浅拷贝或者深拷贝的一个实现逻辑。
深拷贝方法很多,比如序列化的方式,先把对象序列化一遍,然后再通过反序列化回来。就会得到一个完整的新的对象。或者在clone()方法里面重写克隆逻辑。对克隆对象的内部引用变量,再次进行克隆
聊一聊你的设计模式?
创建模式:是对对象创建过程的各种问题和解决方案的一个总结,包括各种工厂模式,单例模式,构建器模式,原型模式
结构模式:针对软件设计的结构的一个总结,重点关注,对象类继承和组合方式的一个实践经验的一个总结。
包括桥接模式,适配器模式,装饰器模式,代理模式,组合模式,外观模式,享元模式
行为型模式,是从类或者对象之间的一个交互,职责划分等角度的总结的一个模式。
策略模式,解释器模式,命令模式,观察者模式,迭代器模式,模板方法模式,访问模式。
什么是观察者模式和策略者模式?
策略模式主要是根据上下文动态控制类的行为。一般是可以解决多个if else判断带来的代码复杂性和维护性问题。另一方面,把类的不同行为进行封装,使得程序可以进行动态的扩展和替换,增加了程序的灵活性。比如支付理由,可以使用策略模式进行实现。
观察者模式,一对多的对象依赖关系中实现某一个对象状态变更之后的感知的场景。一方面可以降低对象依赖关系的耦合度,弱化依赖关系。另一方面,通过这种状态机制,可以保证这些依赖对象之间的状态协同。
java有几种拷贝方式?
- 使用java.io包下的库,使用FileInputStream读取,再使用FileoutPutStream写出
- java.nio包下的库,使用transferTo或transformFrom方法实现。
- java标准类库本身提供的Files.copy的实现
接口和抽象类的区别是什么
接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),抽象类可以有非抽象的方法
接口中的实例变量默认是 final 类型的,而抽象类中则不一定
一个类可以实现多个接口,但最多只能实现一个抽象类
一个类实现接口的话要实现接口的所有方法,而抽象类不一定
接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
final finally finalize区别
final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法
finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调用System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的最后判断。
bio和nio区别
- BIO是阻塞的,NIO是非阻塞的.
- BIO是面向流的,只能单向读写,NIO是面向缓冲的, 可以双向读写
- 使用BIO做Socket连接时,由于单向读写,当没有数据时,会挂起当前线程,阻塞等待,为防止影 响其它连接,,需要为每个连接新建线程处理.,然而系统资源是有限的,,不能过多的新建线程,线 程过多带来线程上下文的切换,从来带来更大的性能损耗,因此需要使用NIO进行BIO多路复用, 使用一个线程来监听所有Socket连接,使用本线程或者其他线程处理连接
select 和 epoll 的区别?
select和epoll都是io多路复用。可以让一个线程监听多个文件描述符的io事件或者连接事件。
只要一个或者多个文件描述对象符就绪,就会触发阻塞唤醒。使得应用程序直接进行数据的读取或者写入。
- select是基于轮询的机制,它需要遍历整个监听集合,知道找到就绪的文件描述符,而epoll是基于事件通知机制,它只需要遍历当前就绪的文件符号集合,大大减少遍历的次数和开销
- select的集合大小受到操作系统限制,epoll没有这个限制,可以监听大量的文件描述符。
- 在处理大量文件描述符时,select的性能随着监听集合的增大而逐渐下降,而Epoll的性能则能够保持稳定。
- 在多线程环境下,select需要将监听即可传递给每个线程,而epoll可以在一个线程中处理多个文件描述符,避免了线程间的切换和数据复制等开销
什么是零拷贝?
我们需要把磁盘的某个内容,发送打破远程服务器上,它必须经过几个拷贝过程。
- 从磁盘中拷贝内容到内核缓冲区,cpu控制器在把数据复制到用户空间的缓冲区里面。
- 再用程序里面调用write()方法,把用户缓冲区的内容拷贝到内核区的socketBuffer里面。
- 最后把内核区下的socketBuffer中的数据复制到网卡缓冲区,
- 网卡缓冲区再把数据赋值到目标服务器上。
数据拷贝至少要经历4次拷贝。其中两次拷贝属于浪费,用户空间到内核空间,内核空间到用户空间,设计到线程的上下文切换。对CPU的性能造成一定的影响。
零拷贝可以直接把内核区的数据直接传输给Socket,而不在经过应用程序所在的用户空间。零拷贝通过DMA技术把文件内容复制到内核空间的ReadBuffer。接着把包含数据位置和长度细腻系的文件描述符加载到socketbuffer里面。DMA引擎可以直接把数据从内核空间传递到网卡设备。
Zero Copy的数据传输方式
java.nio.channels.FileChannel 中定义了两个方法:transferTo( )和 transferFrom( )。transferTo( )和 transferFrom()方法允许将一个通道交叉连接到另一个通道,而不需要通过一个中间缓冲区来传递数据。只有 FileChannel 类有这两个方法,因此 channel-to-channel 传输中通道之一必须是 FileChannel。您不能在 socket 通道之间直接传输数据,不过 socket 通道实现WritableByteChannel 和 ReadableByteChannel 接口,因此文件的内容可以用 transferTo( ) 方法传输给一个 socket 通道,或者也可以用 transferFrom( )方法将数据从一个 socket 通道直接读取到一个文件中。
8个基本数据类型
boolean,byte,char,shot ,int ,long ,double,float
volatile关键字有什么用?
可以保证多线程环境下共享变量的可见性。cpu里面设置了三级缓存区解决cpu运算效率和内存IO效率的问题。但是也带来了缓存一致性的问题。而在多线程并行的情况下,缓存一致性问题就会导致可见性的问题。添加了volite关键字的变量,JVM会自动增加一个#lock汇编指令。而这个指令会根据cpu不同型号去自动添加总线锁或者缓存锁
通过增加内存屏障防止多个指令之间的重排序
指令的编写顺序和执行顺序是不一致的。从而在多线程环境下导致可见性问题。指令重排序本质上是一种性能优化的手段。
为什么重equals()一定要重写hashcode()方法?
如果只重写euqals方法,而不重写hashcode方法。就有可能导致a.equals(b)这个表达式不成立,但是hashCode却不同。在进行散列存储的时候会出现问题。散列存储是使用hashCode的方式来计算key的存储位置的。如果两个相同的对象,但是有不同的hashcode就会导致这2个对象存储在hash表的不同位置。
java SPI是什么?
Java提供的一些接口扩展机制,
- 把标准定义和接口实现分离,在模块化开发中很好的实现了解耦。
- 实现功能的扩展,更好的满足定制化的需求。
请说一说对象的创建过程
类加载检查:在实例化一个对象时,JVM会检查目标对象是否已经被加载并初始化,如果没有,JVM需要做的是立刻去加载目标类,然后去调用目标类的构造器,去完成初始化。目标类的加载是通过类加载器来实现的,主要就是把一个类加载到内存里面,然后是初始化的过程,主要是对目标类里面的静态变量,成员变量,以及静态代码块进行初始化,
分配内存空间:当目标类初始化过后,就可以从常量池里面找到对应的类元信息,目标类大小在类加载完成之后就已经确定了,需要为新创建的对象根据目标对象的大小,在堆内存里面分配内存空间。内存分配方式一般有2种。第一种是指针碰撞,第二种是空闲列表,JVM会根据堆内存是否规整来决定内存的分配对象。
初始化零值:JVM会将类中的普通成员变量初始化,int类型初始化为0。保证实例化后的对象不同初始化就可以直接使用。
设置对象头:JVM还需要对对象的对象头做一个设置,对象所属的类元信息,对象的GC分代年龄,hashcode,锁标记。JVM的工作就结束了,然后就是执行目标对象内部生成的init方法。执行构造块,调用构造函数,完成对象的创建。
序列化和反序列化的理解
为了解决网络通信之间的一个对象传输的问题,把当前JVM进程里面的一个对象跨网络传输到另一个JVM进程中进行恢复。
- 序列化,就是把内存里面的对象转化为字节流,以便用来实现存储和传输,而
- 反序列化就是根据从文件或者网络上获取到的对象的一个字节流。根据字节流里面保存的对象描述信息和状态,重新构建成一个新的对象。序列化的前提是为了保证通信双方,对于对象的一个可识别性,所以我们会把对象先转化为通用的解析格式。比如说json,xml等。从而实现跨语言,跨平台的可识别性。
序列化的选择:序列化之后的数据大小,因为数据大小会影响传输性能,序列化的性能,序列化耗时较长会影响业务的性能,是否支持跨平台和跨语言。技术的成熟度。
序列化和反序列化为什么要实现Serializable接口?
在java中实现Serializable是为了支持对象的序列化和反序列操作。Serializable是JAVA提供的标记接口,没有任何方法,只是起到一个标记作用,当一个类实现了Serializable接口的时候表明这个类的对象可以被序列化成字节流,或者从字节流反序列化还原成对象。
- 可以保证只有那些被设计为可序列化的类对象才能被序列化
- 规范了类的行为,表明该类的对象可以被序列化
经常会看到一些实现了
Serializable的类中,都有一个名为serialVersionUID类型为long的私有静态 属性。该属性修饰符里使用了final即赋值后不可更改。Java 的对象序列化 API 在从读取到的字节序列中反序列化出对象时,使用 serialVersionUID 这个静态类属性来判断:是否序列化对象时使用了当前相同版本的类进行的序列化。Java 使用它来验证保存和加载的对象是否具有相同的属性,确保在序列化上是兼容的。
为什么两个Interge不能使用==来解析
Integer引入一个享元模式的设计,对-128到127之间的数据做了一层缓存,也就是说Integer类型的目标值在-128到127之间,就直接从缓存里获取数据就直接返回一个Integer这样一个对象的实例。并且返回。否则会创建一个新的Integer对象。这样创建的好处,就是就按少频繁创建Integer对象,带来的内存消耗
new String("abc")创建了几个对象
会根据已经加载的系统类String,在堆内存里面去实例化一个字符串对象,然后在String的构造方法里面呢。传递了abc的一个字符串常量池,因为字符串里面的成员变量是final修饰的,所以是一个字符串常量,JVM会拿字面量"abc"去字符串常量池里面去试图找到对应它 的String的对象引用。如果拿不到就会在堆内存里面去创建一个“abc"的String对象。并且把引用保存到字符串常量池里面。
- 如果'abc'这个字符串常量不存在,则创建2个对象,分别是'abc'这个字符串常量,已经'new String'这个实例对象
- 如果'abc'这字符串常量存在,则只会创建一个对象
jdk动态代理只能代理有接口的类
java实现动态代理是Proxy.newProxyInstance()这个方法实现的。它需要传入被动态代理的一个接口类。之所以要传入接口而不能传入类。jdk底层实现会在程序运行期间,去动态生成一个代理类,叫做$Proxy0。那么这个动态生成的代理类,会去继承一个java.lang.reflect.Proxy这样的一个类。同时还会去实现被代理类的接口。在java里面是不支持多种继承的,而每个动态代理类都继承了一个Proxy,所以动态代理只能代理接口,而不能代理实现类。
finally语句块一定会执行吗?
- 程序没有进入进入到try语句块因为异常导致程序终止,这个问题主要是开发人员在编写代码的时候异常捕获的范围不够
- 在try或者cache语句块中,执行了System.exit(0)语句,导致JVM直接退出
Interger和int的区别
Interger是int类型的封装类,
- int类型可以直接定义变量名赋值即可,Interger需要new关键字对象。
- 基本类型和Interger混合使用时,Java会自动通过拆箱和装箱实现类型转换,
- Integer作为对象类型,封装了一些方法和属性,我们可以利用这些方法来操作数据。作为成员变量,
- Integer的默认值是null,而int的默认值是0。
- Integer存储在堆内存中,int直接存储在栈空间。
java有几种文件拷贝方式.那一种效率最高
- 我们使用java.io包下的库,使用FileInputStream读取,再使用FileOutputStream写出
- 使用java.nio包下的库,使用transferto或transfrom方法实现。
- java标准库本身提供了Files.copy()实现。
什么是幂等,如何解决幂等性问题?
方法被多次调用,所产生的影响一样,之所以会有这样子的原因,是因为在网络通信里面,存在2种行为。导致接口被多次调用
1.是用户的重复提交或者用户的恶意攻击,导致这个请求会被多次重复执行
2.在分布式架构中,为了避免网络通信导致的数据丢失,在服务之间进行通信的时候会涉及超时重试的机制,而这种机制有可能导致服务端接口被重复调用。
数据库的唯一约束实现幂等,比如对于数据插入类的场景,比如常见订单,因为订单号肯定是唯一的,所以如果是多次调用就会触发数据库的唯一约束异常。
使用redis里面提供的setnx指令,比如对于MQ消费的场景,为了避免MQ重复消费导致数据多次被修改的问题,可以在接受到MQ的消息时,把消息通过setnx写入到redis里面,一旦这个消息被消费国,就不会被再次消费。
使用状态机来实现幂等,所谓状态机是指一条数据的完整运行状态的转换流程,比如订单状态,因为他的状态只会向前变更。
为啥jdk9要把string的底层由char[]变成bytes[]
jdk9 并没有将String的底层实现有char[] 改成byte[],而是在jdk9中,引入了一个compact strings的优化,优化的目的是减少string对象的内存消耗。
==和equals的区别吗?
对于基本类型== 比较的是值是否相同。引用类型,比较的是引用是否相同。
equals 默认情况下是引用比较,只是很多类重写了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下 equals 比较的是值是否相等。
final的特点
3. 集合(需要准确优化)
concurrentHashmap底层?
ConcurrentHashMap 是线程安全的哈希表,它是 Java 并发包中提供的一种高效的并发 Map 实现。ConcurrentHashMap 底层采用了分段锁的机制,不同的段(Segment)可以被不同的线程同时访问,从而提高了并发性能。
JDK1.7 中的 ConcurrentHashMap 是由
Segment数组结构和HashEntry数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一段数据时,其他段的数据也能被其他线程访问,实现了真正的并发访问。
在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的Node数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用
CAS + synchronized实现更加细粒度的锁。将锁的级别控制在了更细粒度的哈希桶数组元素级别,也就是说只需要锁住这个链表头节点(红黑树的根节点),就不会影响其他的哈希桶数组元素的读写,大大提高了并发度。
Java 8 中的 ConcurrentHashMap 实现采用了基于 CAS 的方式,其主要实现逻辑如下:
- ConcurrentHashMap 内部采用了一个数组来存储数据,每个数组元素称为一个“桶”,每个桶又是一个链表或红黑树,用于存储键值对。数组的大小会根据当前元素数量动态调整。
- ConcurrentHashMap 中的每个桶都有一个链表或红黑树,用于存储键值对。当链表长度超过阈值(默认为 8)时,会将链表转换为红黑树,以提高查找效率。
- ConcurrentHashMap 中的每个桶都有一个“基准计数”,用于记录该桶中键值对的数量。同时,每个线程都会维护一个“本地计数”,用于记录该线程向 ConcurrentHashMap 中插入的键值对数量。
- ConcurrentHashMap 中的 put 操作会先根据 key 的哈希值找到对应的桶,然后对该桶进行加锁(采用了一种乐观锁的方式,即不断尝试 CAS 操作),如果加锁成功,则进行插入操作。插入操作包括两个步骤:首先将键值对插入到桶中,然后将“基准计数”加 1。如果加锁失败,则重试插入操作。
- ConcurrentHashMap 中的 get 操作也会先根据 key 的哈希值找到对应的桶,然后对该桶进行加锁,如果加锁成功,则在该桶中查找对应的键值对。查找操作包括两个步骤:首先遍历链表或红黑树,查找对应的键值对;然后将“本地计数”加 1。如果加锁失败,则重试查找操作。
- ConcurrentHashMap 中的扩容操作会将所有的桶都进行扩容,扩容时会对每个桶进行加锁,不同的桶可以被不同的线程同时扩容。扩容操作包括两个步骤:首先将旧桶中的键值对重新分配到新桶中,然后将“基准计数”更新为新桶中键值对的数量。
concurrentHap底层实现原理
concurrentHashMap底层是由数组,单向链表和红黑树组成。
当初始化一个map的时候,默认会初始化一个长度等于16的数组。
当链表长度过长的时候,引入了红黑树这样的一个机制。当数组长度大于64,链表的长度大于等于8 的时候,单向链表会转换成红黑树。当动态扩容后,红黑树可能退化成链表。
concurrentHashMa提供了并发安全的一个实现,主要是对Node进行加锁来保证数据的安全性。它锁的粒度是数组中的某一个节点。
当数组长度不够的时候,需要对数组进行扩容。在实现上,concurrentHashMap引入看多线程并发扩容的一个实现。多个线程对原始数组进行分片,每个线程负责一个分片的数据迁移。
cuncurrentHashMap有个size()方法去获取总的元素个数,当线程竞争不激烈的情况下,使用CAS的方式进行元素个数的递增。当线程竞争激烈的情况下,使用一个数组来维护元素的个数。如果要增加元素的个数的时候,直接从数组中随机选择一个,再通过CAS算法来实现原子递增。思想就是使用数组来实现并发更新的一个负载。
concurrentHashMap
与JDK7相比,少了Segment分段锁这一层,直接操作Node数组(链表头数组),后面称为桶
- 针对读操作,通过UNSAFE.getObjectVolatile原子读语义获取最新的value
- 针对写操作,由于采用懒惰加载的方式,刚初始化时只确定桶的数量,并没有初始默认值。当需要put值的时候先定位下标,然后该下标下桶的值是否为null,如果是,则通过UNSAFE.comepareAndSwapObject(CAS)赋值,如果不为null,则加Synchronized锁,找到对应的链表/红黑树的节点value进行更改,后释放锁
concurrentHashMap扩容原理?
- 通过计算 CPU 核心数和 Map 数组的长度得到每个线程(CPU)要帮助处理多少个桶,并且这里每个线程处理都是平均的。默认每个线程处理 16 个桶。因此,如果长度是 16 的时候,扩容的时候只会有一个线程扩容。
- 初始化临时变量 nextTable。将其在原有基础上扩容两倍。
- 死循环开始转移。多线程并发转移就是在这个死循环中,根据一个 finishing 变量来判断,该变量为 true 表示扩容结束,否则继续扩容。
- 3.1 进入一个 while 循环,分配数组中一个桶的区间给线程,默认是 16. 从大到小进行分配。当拿到分配值后,进行 i-- 递减。这个 i 就是数组下标。(
其中有一个 bound 参数,这个参数指的是该线程此次可以处理的区间的最小下标,超过这个下标,就需要重新领取区间或者结束扩容,还有一个 advance 参数,该参数指的是是否继续递减转移下一个桶,如果为 true,表示可以继续向后推进,反之,说明还没有处理好当前桶,不能推进)- 3.2 出 while 循环,进 if 判断,判断扩容是否结束,如果扩容结束,清空临死变量,更新 table 变量,更新库容阈值。如果没完成,但已经无法领取区间(没了),该线程退出该方法,并将 sizeCtl 减一,表示扩容的线程少一个了。如果减完这个数以后,sizeCtl 回归了初始状态,表示没有线程再扩容了,该方法所有的线程扩容结束了。(
这里主要是判断扩容任务是否结束,如果结束了就让线程退出该方法,并更新相关变量)。然后检查所有的桶,防止遗漏。- 3.3 如果没有完成任务,且 i 对应的槽位是空,尝试 CAS 插入占位符,让 putVal 方法的线程感知。
- 3.4 如果 i 对应的槽位不是空,且有了占位符,那么该线程跳过这个槽位,处理下一个槽位。
- 3.5 如果以上都是不是,说明这个槽位有一个实际的值。开始同步处理这个桶。
- 3.6 到这里,都还没有对桶内数据进行转移,只是计算了下标和处理区间,然后一些完成状态判断。同时,如果对应下标内没有数据或已经被占位了,就跳过了。
- 处理每个桶的行为都是同步的。防止 putVal 的时候向链表插入数据。
- 4.1 如果这个桶是链表,那么就将这个链表根据 length 取于拆成两份,取于结果是 0 的放在新表的低位,取于结果是 1 放在新表的高位。
- 4.2 如果这个桶是红黑数,那么也拆成 2 份,方式和链表的方式一样,然后,判断拆分过的树的节点数量,如果数量小于等于 6,改造成链表。反之,继续使用红黑树结构。
- 4.3 到这里,就完成了一个桶从旧表转移到新表的过程。
jdk1.8中 concurrentHashMap是如何保证线程安全的?
主要利用Unsafe操作+synchronized关键字。 Unsafe操作的使用仍然和JDK7中的类似,主要负责并发安全的修改对象的属性或数组某个位置的值。 synchronized主要负责在需要操作某个位置时进行加锁(该位置不为空),比如向某个位置的链表进行插入结点,向某个位置的红黑树插入结点。
- 储存Map数据的数组时被volatile关键字修饰,一旦被修改,其他线程就可见修改。因为是数组存储,所以只有改变数组内存值是才会触发volatile的可见性
- 如果put操作时hash计算出的槽点内没有值,采用自旋+CAS保证put一定成功,且不会覆盖其他线程put的值
- 如果put操作时节点正在扩容,即发现槽点为转移节点,会等待扩容完成后再进行put操作,保证扩容时老数组不会变化
- 对槽点进行操作时会锁住槽点,保证只有当前线程能对槽点上的链表或红黑树进行操作
- 红黑树旋转时会锁住根节点,保证旋转时线程安全
ConcurrentHashMap 和HashMap的扩容有什么不同?
HashMap的扩容是创建一个新数组,将值直接放入新数组中,JDK7采用头链接法,会出现死循环,JDK8采用尾链接法,不会造成死循环 ConcurrentHashMap 扩容是从数组队尾开始拷贝,拷贝槽点时会锁住槽点,拷贝完成后将槽点设置为转移节点。所以槽点拷贝完成后将新数组赋值给容器。
HashMap底层原理
HashMap是基于哈希表的Map接口的非同步实现。HashMap是一个存储key-value键值对的集合,每一个键值对也叫做entry,这些entry分散存储在一个数组中,这个数组也是HashMap的主干,这个数组每个元素的初始值都是null。
hashmap和hashtable的区别
- HashTable是线程安全的,而HashMap不是,HashMap的性能要比HashTable更好,因为HashMap采用了全局同步锁来保证安全性,对性能影响较大
- HashTable采用数组+链表,HashMap底层采用数组+链表+红黑树
- HashMap的初始容量是16,HashTable初始容量是11
- HashMap可以使用null作为key,而HashTable不允许.
- HashTable的直接使用key的hashcode对数组长度做取模,HashMap对hashcode做了二次散列,从而避免了key分布不均匀影响查询性能。
hashtable和ConcurrentHashMap的区别?
Hashtable 和 ConcurrentHashMap 都是 Java 中用于存储键值对的类。虽然它们都提供了线程安全的访问机制,但它们之间存在一些重要的区别:
线程安全性:Hashtable 的所有方法都是同步的,这意味着在多线程环境下,多个线程可以安全地访问 Hashtable 的同一实例。而 ConcurrentHashMap 采用了一种不同的机制,它将整个 Map 分成了若干小块,每个小块都由一个独立的锁来控制。这种机制使得多个线程可以同时访问 ConcurrentHashMap 的不同部分,从而提高了并发访问效率。- 性能:由于 Hashtable 的所有方法都是同步的,因此在
高并发环境下,访问 Hashtable 的性能会受到较大的影响。而 ConcurrentHashMap 采用了分块锁的机制,因此在高并发环境下,它的性能比 Hashtable 要好得多。- 允许 null 值:
Hashtable 不允许键或值为 null,否则会抛出 NullPointerException 异常。而 ConcurrentHashMap 允许键和值都为 null。- 迭代器:Hashtable 的迭代器是 fail-fast的,也就是说,如果在迭代的过程中对 Hashtable 进行了修改,迭代器会立即抛出 ConcurrentModificationException 异常。而 ConcurrentHashMap 的迭代器是 weakly consistent 的,也就是说,它不保证在迭代过程中看到的所有元素都是最新的。
综上所述,虽然 Hashtable 和 ConcurrentHashMap 都提供了线程安全的访问机制,但
ConcurrentHashMap 在性能和功能上都比 Hashtable 要更优秀。因此,如果需要在高并发环境下使用 Map,建议使ConcurrentHashMap。
CopyOnWriteList
CopyOnWrite顾名思义即写时复制策略
针对写处理,首先加ReentrantLock锁,然后复制出一份数据副本,对副本进行更改之后,再将数据引用替换为副本数据,完成后释放锁
针对读处理,依赖volatile提供的语义保证,每次读都能读到最新的数组引用
hashmap闭环?
但是这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
ArrayList 和 HashSet 的 contains 的时间复杂度
contains()方法通过调用indexOf()方法来判断,而后者需要遍历数组,因此ArrayList的contains()方法的时间复杂度为O(n)
当没有哈希冲突时:调用contains(object)方法时,先调用object的hashCode()方法计算哈希值1,此哈希值经过某种算法(hash())之后,得到哈希值2,哈希值2再经过indexFor()之后得到数组的索引,然后object与索引位置上的元素用equals()方法比较,此时的时间复杂度为O(1) 当产生哈希冲突时,链表个数小于8.时间复杂度O(1)。当链表元素个数>=8,并且数组元素达到64。时间为O(logn)
Arraylist与LinkedList有什么区别?
- 内部的实现方面,Arraylist是一个数组实现。LinkedList是一个双向链表实现的
- 时间访问复杂度不同:Arraylist访问是O(1),LinkedList是O(n)
- 空间占用不同:LinkedList通过链表链接元素,每个元素都包含前后节点的引用,所以占用空间较大
hashmap中的hash方法为什么要右移动16位异或
是为了让hash值的散列度更高。尽可能的去减少hash表的hash冲突,put方法里面是通过key的hash值与数组的长度取模运算得到的长度。一般n的值一般小于2^16次方,也就是65536。也就是说位置始终是使用hash的值的16低16位与n-1进行取模计算。造成key散列度不高。
右移16后,也就是高位的数据变成低位再与 hashcode进行异或运算,就相当于把低位和高位的特征进行了一个组合。组合后hashcode的散列度更加高
一致性hash算法的理解
一致性hash是一种比较特殊的hash算法。它的核心思想是在解决分布式环境下,hash表可能存在的动态扩容和缩容的一个问题,当节点数量出现上述情况,原本的映射关系就会发生变换。也就是对所有数据按照新的节点数量来重新映射一遍,这就涉及到一个大量数据迁移的问题和重新映射的问题。
一致性hash算法就是用来优化这样子的 场景的。具体工作原理非常简单,一致性hash是通过一个hash环的数据结构来实现的。环的起点是0,终点是2^32-1。当节点落下后,哦们对key进行hash。目标key会按照顺时针去找到离自己最近的一个节点来进行顺序存储。当新增一个节点,我们只需要重新计算新增节点附近的值。只有少部分的数据进行重新映射和迁移。一致性hash算法的好处是扩展性好
ArrayList的自动扩容机制?
ArrayList是一个数组存储容器,默认的数组长度是10.当数据超过默认长度时,会触发自动扩容,首先创建一个新数组,这个新数组的长度是原来数组长度的1.5倍。然后使用Arrays.copyof方法把老数组里面的内容拷贝到新数组里面。然后在把新添加的元素添加到新数组里面。
HashMap 为什么在链表长度为 8 的时候转红黑树,为啥不能是 9 是 10?
如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。 所以说如果一个桶里面的链表长度超过了8,那么很有可能是用户的哈希算法实现有问题。 链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低, 而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
hashmap每次扩容为啥库容是2倍?
HashMap扩容主要是给数组扩容的,因为数组长度不可变,而链表是可变长度的。从HashMap的源码中可以看到HashMap在扩容时选择了位运算,向集合中添加元素时,会使用(n - 1) & hash的计算方法来得出该元素在集合中的位置。只有当对应位置的数据都为1时,运算结果也为1,当HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞
hashmap的get过程?
hashmap的扩容过程?
4. 反射
反射是怎么实现的?
Java反射机制的原理主要是通过Class类来实现的。
- 使用Class.forName()方法获取Class对象。
- 使用类名.class获取Class对象。
- 使用对象.getClass()方法获取Class对象。
什么是代理模式?
在开发过程中,当我们要访问目标类的时候,不是直接访问目标类,而是访问代理类,通过代理类调用目标类来完成的。简单来说就是直接调用变成间接调用。这样子做的最大好处就是在代理类调用目标类之前和之后去添加一些预处理和后处理的操作,来扩展一些不属于目标量的功能。比如在调用方法之前记录日志,在方法执行前进行额外的参数校验。进行事务管理,权限校验等。
了解什么是动态代理吗?
代理模式字实现方式上,又会分成静态和动态。所谓静态就是在程序执行之前,我们就给目标类编写了其代理类的代码,编译了代理类。这样子就是在程序运行之前,我们已经生成了代理类的字节码文件。在程序运行的时候,直接去读这些字节码文件进行运行。如果是静态代理的话,我们需要编写一个与其绑定的代理类。
动态代理是一种设计模式,它允许在
运行时创建代理对象,代理对象可以在不改变原始对象的情况下拦截并修改其行为。动态代理通常用于解耦和增强原始对象的功能。在Java中,动态代理由java.lang.reflect包提供支持。通过使用接口和
InvocationHandler接口,可以在运行时动态地生成代理类和代理对象。当客户端调用代理对象的方法时,代理对象将代理实际的对象,并在调用前后执行额外的逻辑。
基于JDK和基于cglib的动态代理的区别
Jdk动态代理:利用拦截器(必须实现InvocationHandler接口)加上反射机制生成一个代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
Cglib动态代理:利用ASM框架,对代理对象类生成的class文件加载进来,通过修改其字节码生成子类来进行代理。在大多数情况下,Cglib代理比JDK动态代理更适合于大规模的方法拦截和增强等场景
- 如果想要实现JDK动态代理那么代理类必须实现接口,否则不能使用;
- 如果想要使用CGlib动态代理,那么代理类不能使用final修饰类和方法
Spring AOP
1、如果目标对象实现了接口,默认情况下会采用JDK的动态代理 2、如果目标对象实现了接口,也可以强制使用CGLIB 3、如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换
java的反射的优缺点
优点:
- 增加程序的灵活性,可以在运行的过程中动态对类进行修改和操作
- 提高代码的复用率,比如动态代理,就是用到了反射来实现
- 可以在运行时轻松获取任意一个类的方法,属性,并且还能通过反射进行动态调用
缺点
- 反射会涉及到动态类型的解析,所以JVM无法对这些代码进行优化,导致性能要比非反射调用更低,
- 使用反射以后,代码的可读性会下降
- 反射可以绕过一些限制访问的数下或者方法,可能会导致破坏了代码本身的抽象性
5. JUC
线程池
线程池是如何实现回收的?
线程池里面的线程分为核心线程和非核心线程,它有2种方式进行初始化,第一种是向线程池里面添加任务的时候,被动初始化。
主动调用'prestartAllCareThreads'方法。
当线程池的队列满的情况下,为了满足线程的并发处理能力,线程池会增加非核心线程。非核心线程数量和核心线程数量之和不会超过最大线程数量这个参数。当任务处理完成,工作线程处于空闲状态的时候,就会去回收。这个功能是通过阻塞队列里面的poll方法来完成的,这里面的方法提供了一个超时时间和超时单位这样个参数,当前线程在规定时间内没有从阻塞队列这里满获取对象的时候,那么poll方法会返回null。从未完成线程的回收。
为什么要使用线程池?线程池的工作原理?
线程池本质是一种池化技术,池化技术是一种资源复用的设计思想,比较常见的池化技术有连接池,内存池和对象池。而线程池里面复用的是线程资源
- 减少线程的频繁创建和销毁带来的性能开销,因为线程创建会涉及到CPU上下文切换,内存分配等工作
- 线程池本身会有参数来控制线程的创建的数控,这样就可以比曼无休止的创建线程带来的资源利用率过高的,起到资源保护的作用
线程池里面的工作线程是 根据任务数量来决定阻塞和唤醒的,从而达到线程复用的一个目的。
线程池有哪些参数可以设置?
corePoolSize:核心线程数,线程池中始终保持的活动线程数,即使线程是空闲的也不会被回收。
maximumPoolSize:线程池中最大线程数,当任务数量超过核心线程数并且任务队列已满,线程池会创建新的线程直至达到最大线程数。
keepAliveTime:超过核心线程后空闲线程的最大存活时间,超过此时间,空闲的线程将会被终止。
workQueue:工作队列,用来存放等待执行的任务的队列。
unit:指定空闲线程存活时间的单位,如秒,毫秒等。
threadFactory:线程工厂,用来创建新线程的工厂类。
handler:拒绝策略,当工作队列已满且工作线程等于最大线程数,,对于新任务的处理策略,可以选择阻塞、异常、丢弃等方式。
AbortPolicy不执行此任务,而且直接抛出一个运行时异常。适用于对任务丢失敏感的场景,当线程池无法接受新任务时,希望立即知道并处理该异常。
DiscardPolicy:新任务被提交后直接被丢弃掉,并且不会抛出异常,无法感知到这个任务会被丢弃,可能造成数据丢失。使用场景:适用于对任务丢失不敏感的场景,当线程池无法接受新任务时,简单地丢弃被拒绝的任务。
DiscardOldestPolicy:会丢弃任务队列中的头结点,通常是存活时间最长并且未被处理的任务。使用场景:适用于对新任务优先级较高的场景,当线程池无法接受新任务时,会丢弃一些等待时间较长的旧任务,以便接受新任务。
CallerRunsPolicy:当有新任务提交后,如果线程池没被关闭且没有能力执行,则把这个任务交于提交任务的线程执行,也就是谁提交任务,谁就负责执行任务。不会抛出异常。使用场景:适用于希望调用者自己处理被拒绝的任务的场景,通常是由调用者自身的线程来执行被拒绝的任务。
- Executors.newFixedThreadPool:创建一个固定大小的线程池,可控制并发的线程数,超出的线程会在队列中等待;
- Executors.newCachedThreadPool:创建一个可缓存的线程池,若线程数超过处理所需,缓存一段时间后会回收,若线程数不够,则新建线程;
- Executors.newSingleThreadExecutor:创建单个线程数的线程池,它可以保证先进先出的执行顺序;
- Executors.newScheduledThreadPool:创建一个可以执行延迟任务的线程池;
1) FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 2)CachedThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
线程池是如何实现复用的?
线程池使用一个生产者和一个消费者去实现线程的一个复用。生成者和消费者模型就是通过一个中间容器来解耦生产者和消费者的一个任务处理的过程。生产者不断生产任务到容器里面,消费者不断从容器里面去消费任务。
所以他使用了阻塞队列来实现这样子的需求,这些任务会保存到线程池的一个阻塞队列里面。消费线程不断从队列里面去取任务去执行。基于阻塞队列这样一个特性,使得阻塞线程里面没有 任务的时候,这些工作线程就会阻塞等待。
阻塞队列的有界和无界
阻塞队列是一种特殊的队列。在普通队列的基础上附加了2种功能,第一个,当队列为空的时候,获取队列中元素的消费者线程他会被阻塞,痛死会唤醒生产者线程。当队列中的元素满的时候,向队列中去添加元素的生产者线程会被阻塞,同时会唤醒者线程。其中阻塞队列中能够容纳的元素个数,通常是有限的,比如我们实例化一个ArrayBlockingList。可以在构造方法中去传入一个整形数字,表示这个基于数组的阻塞队列中,能够容纳的元素个数。无界队列就是没有设置固定大小的队列。只是元素存储量很大,LinkBlockQueue。无界队列在并发的情况下,线程池中几乎可以无限制的添加任务。容易导致内存溢出的问题。
线程上下文中如何传递数据?
- 构造函数或者setter方法传递数据:可以在创建线程对象时通过构造函数或者setter方法将数据传递给线程,
- ThreadLocal:ThreadLocal 可以在每个线程中存储一个对象,并且只有在该线程中才能访问该对象。可以通过 ThreadLocal 的 set() 方法设置数据,get() 方法获取数据。
- 共享变量:可以在多个线程之间共享变量。为了保证共享变量,需要使用同步机制,例如 synchronized 关键字,来保证多个线程同时访问共享变量时不会产生冲突。
什么是线程安全
《Java并发编程实战》一书中,它是这么描述的︰当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替执行,并且在调用代码中不需要任何额外的同步或者协同,这个类都能表现出正确的行为,那么就称这个类是线程安全的。
简单的说,线程安全是指程序在并发环境运行时,多线程之间能够正确的处理共享变量,程序总是表现出正确完成的行为。注意关键词:并发环境、多线程、共享变量、正确完成。这里所谓的正确完成,就是要保证并发的三大特性∶
原子性、可见性、有序性。
sleep()和wait()的区别和会不释放锁
1、sleep是线程中的方法,但是wait是Object中的方法。 2、sleep方法不会释放资源锁,但是wait会释放资源锁,而且会加入到等待队列中。 3、sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字。 4、sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
为什么wait()和notify()需要再synchronized里面
wait()和notify是为了实现多个线程之间的一个协调。wait表示线程进入到阻塞状态,notify让阻塞的线程被唤醒。从而 去实现多个线程之间的一个通信。线程之间进行通信,除了管道流之外,只能通过共享变量的方式。
线程通信必须要有一个静态条件去控制线程什么时候条件等待,什么时候条件唤醒。而synchronized同步关键字就可以实现这样一个互斥的条件。
锁
synchronized锁升级原理?
synchronized在jdk1.6版本以前,是通过重量级锁来试下线程之间的一个锁的竞争。之所以是重量级锁,底层是基于操作系统层面的mutex lock,来去实现互斥锁的一个功能。由于权限隔离关系,应用程序调用系统方法的时候,需要切换到内核态来执行,jdk1.6之后,synchronized会根据线程竞争的情况,先尝试不加重量级锁的情况下,去保证线程安全性。引入了偏向锁和轻量级锁这样一个机制。偏向锁就是把某个锁偏向某个线程,就是通过CAS机制来修改偏向锁的一个标记。这种锁适合在同一个线程多次去申请同一个锁资源的情况。并且没有其他线程竞争的有一个场景中。轻量级锁也可以称为自旋锁。它是基于自适应自选的机制。自旋锁的状态可以避免用户态到内核态。切换带来的一个性能的损耗。如果有线程去竞争锁,synchronized会尝试使用偏向锁的方式去竞争锁资源,如果能够竞争到偏向锁,则表示加锁成功,直接返回就好了。如果竞争偏向锁失败,当前已经有其他线程占用的偏向锁。那么就需要将锁升级到轻量级锁,在竞争锁的线程会根据自适应自选次数会尝试自旋占用锁资源,如果在轻量级锁的状态下还是没有竞争锁,只能升级到重量级锁。没有竞争到锁的线程会被阻塞,会被Blocking,也就是处于锁等待的一个状态。
操作系统状态?线程池状态,线程状态?
ReentrantLock实现的原理?
什么是ReentrantLock?
ReentrantLock是一个可重入的排他锁,他主要是解决多线程对于共享资源的竞争问题
ReentrantLock的特征?
- 支持重入,也就是获得锁的线程之后,释放锁之前再次去竞争同一把锁的时候,不需要加锁就可以直接访问。
- 它支持公平和非公平特性,
- 它提供了阻塞竞争锁和非阻塞竞争锁的两种方法,分别是lock()和trylock()
实现原理
- 第一个是锁的竞争,ReentrantLock是通过互斥变量使用CAS机制来实现的,没有竞争到锁的线程,会被放入AQS这样一个队列同步器。当锁被释放,会从AQS队列里面的头部去唤醒下一个等待线程,
- 提供了一个公平和非公平的特性,主要区别是竞争的时候,是否去判断AQS里面是否有其他线程。非公平锁是不需要判断的。
- 锁的重入性,在AQS里面有一个成员变量来保存当前锁获取的线程,当同一个线程来竞争的时候,不会走锁的竞争逻辑,而是直接去增加重复次数。
lock和synchroized区别
lock和synchroized都是java中用来解决线程安全问题的一个工具。
synchronized是java中的同步关键字。lock是juc包中提供的接口,而接口有很多实现类,包括reetrantlock这样子的重入锁的实现。
synchronized可以通过2种方式来控制锁的力度。修饰在方法层面,第二种修饰在代码块上。如果锁对象是普通锁,这个锁的范围取决于这个实例的生命周期。lock锁的粒度是根据里面的lock()和unlock()方法实现的,
lock比synchronized灵活性更加高。lock可以自主决定什么时候加锁,什么时候结束。
lock还提供了非阻塞的竞争锁的方法,trylock()。通过返回的true和false来判断当前线程是否已经被加锁。synchronized是关键字 ,无法实现非阻塞竞争锁的方法。synchronized锁的释放是被动的。同步代码块执行结束,或者代码出现异常lock才释放锁。
lock实现了公平锁和非公平锁的。如果当前竞争锁的线程已经存在正在等在锁释放的线程是无法插队的。synchronized只提供了非公平锁的实现
lock和synchronized在性能差别不大。synchronized提供了偏向锁,轻量级锁和重量级锁以及锁升级进行优化。lock使用了自旋锁的方式进行优化
如果一个线程两次调用start(),会出现什么问题?
Java线程一个线程只能调用一次start()方法,第二次调用会抛出一个异常,一个线程是存在生命周期的,在Java里面,线程生命周期包括6种状态,
第一种是new,表示线程被创建还没有被调用。
runnable,这个状态下线程可能正在运行,也可能是在就绪队列里面等待操作系统进行调度分配cpu资源。
block,表示线程处于锁等待状态。
waiting,表示线程处于条件等待状态,当触发条件后唤醒,比如wait()/notify()
time_wait和waitting状态一样,只是多了一个超时条件触发。
最后一个terminated,表示线程执行结束。
再次调用这个线程意思就是让这个可能正在运行的线程重新运行一遍,这是不合理的。
如何中断一个正在运行的线程
- 直接调用Thread方法里面的stop方法可以强制终止正在运行的线程,但是这种方法并不安全,有可能这个线程没有执行完成,导致出现运行结果不正确的现象
- 要想安全地中断一个正在运行的线程,只能在线程里面去埋下一个钩子,外部线程通过钩子触发线程的一个中断命令,java的Thread类里面提供了一个interrupt的方法。这个方法需要配合isinterrupted()方法去使用。就可以实现线程中断。这个不是中断,而是告诉线程你可以结束运行。
线程池如何知道一个线程的任务已经执行完成
从线程池的内部来获取。当我们把一个任务丢给线程池去执行的时候,线程池会调度工作线程,来执行这个任务的run方法。当run方法正常结束以后,也就意味着这个任务完成了,所以线程池中的工作线程,是通过调用任务的run()方法,并且等待run方法返回后,再去统计任务完成的数量
如果想在线程池的外部去获取线程池内部的任务执行状态,
线程池提供了一个isTerminated方法,可以判断线程池的运行状态,我们可以循环地调用这个接口的返回值,来判断程序的运行状态。
在线程中,有一个submit方法,它提供了一个future的返回值,我们可以通过future.get()方法,去获得任务的执行结果。当没有活动结果时,future.get()方法会一直阻塞。直到任务结束。
引入CountDownLatch计数器,可以通过初始化指定的一个计数器,去进行倒计时,它提供了await()阻塞线程,和countDown()去进行倒计时。一旦倒计时为0,所有被阻塞在await()方法的线程都被释放。

线程池中的工作线程中出现异常怎么办?
在Java中,线程池出现问题默认会把异常往外抛,同时这个工作线程也会因为异常而销毁,我们需要自己去处理对应的异常。异常事务中有几种,
- 在传递任务中处理异常,对于进入线程池中的任务,可以提前捕获异常。
- 使用future来获取异常结果
- 我们可以自定义一个Threadfactor的线程工厂,设置一个uncaughtexceptionhandler的方法
什么是死锁?
不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,在没有干预的情况下,线程会一直阻塞,无法往下去执行。
- 互斥条件,一个资源每次只能被一个进程使用
- 请求与保持条件:一个进程因请求资源而阻塞,对已获得的资源保持不释放
- 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺
- 循环等待条件:若干进程之间形成一种头尾详解的循环等待资源关系
解决死锁问题?
预防死锁的方法:
- 破坏请求和保持条件:一次性申请所有资源,之后不在申请资源,如果不满足资源条件则得不到资源分配。
- 破坏不可剥夺条件:当一种进程获得某种不可抢占资源,提出新的资源申请,若不能满足,则释放所有资源,以后需要,再次重新申请
- 破坏循环等待条件:对进程进行拍好,按照序号递增的顺序请求资源。若进程获得序号高的资源想要获取序号低的资源,就需要先释放序号高的资源
避免死锁的方法:
银行家算法
解除死锁的方法
- 资源剥夺
- 终止(撤销)进程:强制将一个或多个死锁进程终止(撤销)并剥夺这些进程的资源,直至打破循环环路,使系统从死锁状态中解脱出来。撤销的原型可以按照进程的优先级和撤销进程代价的高低进行
- 进程回退:让一个或多个进程回退到足以避免死锁的底部
ThreadLocl有哪些应用场景?
是一个基于副本的隔离机制,来班长共享变量修改的安全性,使用场景很多,
- 线程的上下文传递。在跨线程调用的场景中,可以使用ThreadLocal在不修改方法签名的情况下传递线程上下文信息
- 数据库的链接管理。每个线程都可以管理自己的数据信息。比如Mybatis中的sqlsession对象使用了ThreadLocal来存储当前线程的数据库会话信息。
- 事务管理 ,可以使用ThreadLocal来存储事务上下文信息。
ThreadLoal是什么?
ThreadLocal是一个本地线程副本变量的工具类,主要用于将私有线程和该线程存放的副本对象做一个映射,各个线程之间的变量互不干扰,在高并发的场景下,可以实现无状态调用,适用于各个线程不共享变量值的操作
ThreadLocal工作原理是什么?
ThreadLocal:每个线程的内部都维护了一个ThreadLocalMap,它是一个<Key,Value>数据格式,key是弱引用,也就是ThreadLocal本身,而value存的是线程变量的值。
ThreadLocal如何解决Hash冲突?
ThreadLocalMap结构非常简单,处理的方式并非链表而是采用线性探测的方式。所谓线性探测,就是根据初始key的hashcode确定元素在table数组中的位置。如果被占用,则利用固定的算法寻找一定步长的下一个位置,知道找到为止。
ThreadLocal的内存系列
ThreadLocal中的ThreadLocalMap是一个弱引用被Entry中的key引用的。因此如果没有外部强引用来引用它,下次JVM垃圾回收时会被回收。entru中的key被回收,而value又是强引用不会被回收。这样子的话,value一直得不到回收,这样子就会发生内存泄漏。
如何在不加锁的情况下解决线程安全问题?
所谓线程安全问题,就是多个进程对于某个共享资源的访问导致的原子性,可见性和有序性的问题。这些问题会导致共享资源出现一个不可预见性。
一般情况下,为了解决这一问题,是增加同步锁,常见的是像Synchronized,lock等。加锁会涉及到一个性能的消耗。因为加锁会涉及到用户态到内核态的一个转换,以及上下文切换。
为了平衡性能和安全,就出现了无锁并发的概念。
1.通过自旋锁CAS的方式,是指线程在没有抢占锁的情况下。先自选指定次数获取锁。2.使用乐观锁,给数据添加一个version版本号,如果该数据发生了变化,则去修改这个版本号 3. 在设计中尽量减少共享,从业务上避免并发。
什么是自旋锁?
当线程A想要获取⼀把自旋锁⽽该锁⼜被其它线程锁持有时,线程A会在⼀个循环中自旋以检测锁是不是已经可⽤了。
注意的是:1. 由于自旋锁不释放CPU,因而持有自旋锁的线程应该尽快释放自旋锁,否则等待该自旋锁的线程会一直在自旋,浪费CPU.持有自旋锁的线程在sleep之前应该释放自选锁。
由于JVM实现自旋锁会消耗CPU,如果长时间不调用doNotify方法doWait方慧一直自选,cpu消耗很大。
自旋锁比较适用于锁使用者保持锁较短的情况,这样子自旋锁的效率很高。
什么是CAS?
CAS是
Compare And Swap的缩写(比较在交换),在无锁状态下保证线程操作数据的原子性。解决多线程并行情况下使用锁造成性能损耗的一种机制。它体现的一种乐观锁的思想。
Unsafe是CAS的核心类,由于Java方法无法直接访问底层系统,需要通过本地(native) 方法来访问,Unsafe相当于一个后门,基于 类可以直接操作特定内存的数据。CAS直接调⽤CPU 的cmpxchg(是汇编指令)指令。优点: 在并发量不是很高的时候可以提高效率。
缺点:1、如果长时间循环对CPU的开销很大。2、只能保证一个共享变量的原子操作 3、ABA问题。一个线程a将数值改成了b,接着又改成了a,此时CAS认为是没有变化,其实是已经变化过了,而这个问题的解决方案可以使用版本号标识,每操作一次version加1。在java5中,已经提供了AtomicStampedReference来解决问题。
第一个是在JUC里面的Atomic是原子实现。第二个是实现多线程对共享资源竞争的互斥性质,比如AQS,ConcurrentHashMap
为什么AQS使用双链表结构存储
双向链表提供了双向指针,可以在任何一个节点方便向前或向后进行遍历,这种对于有反向遍历需求的场景来说非常有用
存储在AQS的线程,可能会出现异常情况,不再需要竞争锁的情况,所以需要把这个异常节点从链表中删除。而删除操作需要找到这个节点的前驱节点。如果不是双向链表,就需要从头节点开始遍历。
新加入的线程在进入到阻塞状态之前,需要判断前驱节点的状态。只有前驱节点是sign状态时,才会让当前线程阻塞。
线程在加入链表 之后,会进入通过自旋的方式尝试竞争锁的方式来提升性能。为了保证竞争的公平性,需要判断当前节点的前驱节点是否是头结点,
6. JVM
OOM如何定位和处理?
确认OOM错误:在应用程序或系统日志中查找相关的错误信息,例如 “OutOfMemoryError”。这可以帮助确认是否真的发生了OOM错误。
分析OOM错误类型:OOM错误通常分为不同的类型,如Java堆内存溢出(Java Heap Space)、Metaspace溢出、栈内存溢出等。根据错误类型,可以确定具体的解决方法。
查看内存使用情况:使用系统监控工具或命令(如top、htop、jconsole等)查看系统的内存使用情况,包括物理内存和交换空间的利用情况,以及进程的内存占用情况。
定位内存泄漏:如果发现内存占用持续增加,可能存在内存泄漏的问题。通过分析堆转储文件(Heap Dump)或使用内存分析工具(如MAT、VisualVM等)来检测和定位内存泄漏的源头。
检查代码逻辑和资源管理:审查应用程序的代码,特别是涉及大量内存使用的部分,例如大对象的创建、文件或数据库连接未正确关闭等。确保及时释放占用的资源,避免不必要的内存占用。
调整内存配置和参数:对于涉及到JVM的应用程序,可以调整JVM的堆内存大小、Metaspace大小、栈大小等参数,以适应实际的内存需求。
优化算法和数据结构:优化代码中的算法和数据结构,以减少内存使用。例如,使用合适的数据结构、缓存策略或分页加载等技术来降低内存消耗。
分布式系统中的OOM:对于分布式系统,注意检查各个组件之间的通信和数据传输,避免单个节点过载导致整个系统OOM。可以考虑增加资源、优化调度策略或进行水平扩展等措施
GC Roots的对象
在Java技术体系里面,固定可作为GC Roots的对象包括以下几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。
- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如 NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
- 所有被同步锁(synchronized关键字)持有的对象。
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
JVM参数
- -Xmx:用于设置JVM的最大堆内存大小。例如,"-Xmx512m"表示将最大堆内存设置为512MB。
- -Xms:用于设置JVM的初始堆内存大小。例如,"-Xms256m"表示初始堆内存为256MB。
- -Xss:用于设置每个线程的堆栈大小。例如,"-Xss1m"表示将堆栈大小设置为1MB。
- -Xmn:用于设置年轻代的堆内存大小。例如,"-Xmn256m"表示将年轻代的堆内存设置为256MB。
- -XX:PermSize:用于设置永久代的初始大小。在Java 8及之后的版本中,永久代已被元空间(Metaspace)取代。 编程导
- -XX:MaxPermSize:用于设置永久代的最大大小。在Java 8及之后的版本中,永久代已被元空间 (Metaspace)取代。
- -XX:MaxMetaspaceSize:用于设置元空间的最大大小。在Java 8及之后的版本中,用于控制元空间大小。
- -XX:NewRatio:用于设置年轻代与老年代的内存比例。例如,"-XX:NewRatio=2"表示年轻代占整个堆内存的 1/3,老年代占2/3。
- -XX:MaxTenuringThreshold:用于设置对象在年轻代中经历多少次垃圾回收后晋升到老年代。默认值通常为―9 15。
- -XX:SurvivorRatio:用于设置Eden区和Survivor区的内存比例。例如,"-XX:SurvivorRatio=8"表示Eden区 占整个年轻代的8/10,每个Survivor区占1/10。
- -XX:+UseConcMarkSweepGC:启用CMS (Concurrent Mark-Sweep)垃圾回收器。
- -XX:+UseG1GC:启用G1 (Garbage-First)垃圾回收器。
- -XX:MaxGCPauseMillis:用于设置垃圾回收的最大暂停时间目标。
- -XX:ParallelGCThreads:用于设置并行垃圾回收线程的数量。
- -XX:+PrintGCDetails:打印垃圾回收详细信息。
java的垃圾回收器有啥?
- serial收集器,它在进行垃圾收集时,会暂停所有的用户线程,知道它完成垃圾回收
- paraller收集器,也叫做吞吐量优先收集器,获取最高的吞吐量,最大限度地减少垃圾收集的时间。
- CMS收集器,也称为并发标记清楚收集器,获取最小的垃圾收集的停顿时间。通过并发的方式去减少垃圾收集的停顿。
- G1收集器,它是一种面向服务器的垃圾收集器,预测垃圾回收的时间,尽可能得减少停顿。
JVM的一次完整的GC是什么?
JAVA内存由新生代和老年代区,新生区又分为eden区和survivor区
一个对象首先会被分配在eden区。如果是大对象直接进入老年代。当eden区空间满了以后,JVM会触发一次Minor GC.用来回收 Eden区内存。eden存活下的对象,会转移到survivor区。每熬过一次minor gc,对象年龄就会增加,如果超过默认的gc次数15次,这个对象就会转移到老年代。当老年代对象满了以后,就会触发一次full gc.
full gc会清理整个堆内存,在full gc之前通常会进行一次young gc。以此来清理eden区和survivor区的垃圾对象。以减少full gc的压力和耗时。在Yong gc以后存活对象将会被复制到survivor区。
JVM三色标记法?
JVM三色标记法是垃圾回收机制里面的一种,主要用来标记内存中存活和需要回收的对象。可以让JVM不发生或仅在短时间发送STW。从而达到垃圾回收的目的。
JVM中的对象分为三种颜色。第一种是白色表示还没有被垃圾回收扫描的对象。第二种是黑色,表示已经被垃圾回收器扫描过,且对象及其引用的其他对象都是存活的。表示已经被垃圾回收器扫描过,但对象引用的其他对象尚未被扫描。
在gc的时候,先把所有对象标记为白色,从根对象开始遍历内核中的对象。将直接引用的对象标记为灰色。然后判断灰色集合中的对象,是否存在子引用。不存在就直接放在黑色集合里。如果存在则需要把对象放在灰色集合中。知道灰色集合中所有对象变成黑色。这一轮标记就完成。还在白色集合中 对象就是不可达对象。可以直接被回收
CMS垃圾回收机制?
CMS是一种低停顿的垃圾回收器。它主要通过初始标记阶段和并发标记阶段。
第一是stop the word。哪些对象是需要回收的。
第二阶段是并发标记。,扫描整个堆中的对象,标记所有不需要回收的对象。不需要stop the word,在程序运行的过程中进行标记
第三个阶段是重新标记。修正并发标记期间。应用程序同步运行导致标记残生变动的那一部分对象。这个阶段需要stop the word
第四个阶段是并发清除操作,CMS会并发执行清除操作,同时应用程序继续执行,最大力度减少对性能的影响。
JVM分代年龄为啥是15次?
在堆内存区分配一块内存空间,当伊甸园内存空间不足的时候,会触发young gc进行对象的回收。而那些因为引用而无法回收的对象,JVM会把他们转移到survivor space里面。survivor分为from 区和to区。刚从伊甸园区转移过来的对象会被分配到from区 。每当触发一次young gc的时候,对象就会在from区和to区来回移动。每移动一次,对象的gc年龄就会加一。默认情况下gc年龄达到15的时候没有被回收。就会移动到老年区。对象的年龄是由对象头进行存储的,在对象头里面是由4个bit来进行表示的,最大表示为15。JVM分代年龄之所以是15次?是因为它最大存储的数值是15。
JVM还引入了动态对象年龄的判断方式。来决定把对象移动到老年代。
强引用,软应用,弱应用,虚引用有什么区别?
不同对象表示对象不同的可达性状态,以及对于垃圾收集的影响。
强应用就是普通对象的引用。垃圾回收器无法回收这一类对象。只有在没有其他引用关系,或者是超过了引用的作用域,显示赋值为null的时候,垃圾回收器此案呢个去进行内存的一个回收。
软引用是一个相互对于强引用的引用,可以让对象豁免一些垃圾收集,只有当JVM内存不足的时候才会去试图回收指向的对象。软引用一般是去实现敏感对象的缓存,
弱引用也是用来描述非必需对象的,当JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference类来表示。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期。在java中用java.lang.ref.PhantomReference类表示。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。虚引用主要用来跟踪对象被垃圾回收的活动。
为什么使用元空间代替了方法区
1.7版本里面的永久代内存是有上限的,虽然可以通过参数来设置,但是JVM加载的class总数大小是很难去确定的,所以很容易出现OOM的一个问题。但是元空间是存储在本地内存里面的,内存上限是比较大的,可以很好地避免这个问题。
永久代的对象是通过fullgc进行垃圾回收的,也就是从老年代同事实现垃圾回收,替换成元空间后,简化了fullgc的这样的一个过程。可以在不暂停的情况下,并发地去释放类的数据。
一个空Object对象,占多大空间
在开启压缩指针的情况下,Object默认会占用12个字节,为避免伪共享的问题,JVM会按照8个字节的倍数进行填充,所以会填充4个字节。变成16个字节的一个长度。在关闭默认指针的情况下呢,Object默认会占16个字节长度。
在hostpot虚拟机里面,一个堆内存布局呢?分为对象头,实例数据,对齐填充。对象头里面有三个部分,一个是markword,类元指针和数组长度。markword存储对象运行时的相关数据,包括锁,hashcode,gc分段年龄。在64位机器中,占用8位字节。数组对象才有的字段,存储数组长度,默认4个字节。
内存泄漏
什么是内存泄漏?导致不需要使用的对象,一直占用JVM内存,并且这块内存无法被回收。导致占用的内存越来越大,导致OOM的现象。
现象:频繁地full gc,full gc 卡顿,年轻代的内存一直在高位无法释放
解决方案:使用jstat命令查看虚拟机中各个区域使用的情况,然后使用dump工具将内存dump下来,使用mat分析工具进行分析
JVM是如何判断一个对象是否可以被回收
引用计数器,为每一个对象添加一个引用计数器,如果当前这个对象存在引用的更新,我们对其+1.这种方式需要额外的空间来存储引用计数器,但是它的实现简单,
当存在循环依赖的清理,就会出现内存泄漏的问题
可达性分析,首先确定一系列肯定不能回收的对象,作为gc root。比如说虚拟机栈中的一个对象,从这个root触发,去寻找它的直接或间接引用对象。当遍历完成后发现一些对象是不可达的。那么我们就认为这些对象已经没有引用了,需要被回收。在垃圾回收的时候,JVM首先会去找到所有的gc root.这个过程会暂停所有的用户线程。也就是stop the world.然后再从gc root这些根节点出发向下搜索。可达对象保留下来。
JVM的组成
类加载器ClassLoader,运行时数据区,执行引擎,本地库接口。jvms首先需要把字节码文件通过类加载器把文件加载到内存的运行时数据区,而字节码文件是jvm的一套指令集,不能直接交于底层操作系统习性,需要命令解释器执行引擎将字节码文件翻译层底层系统命令交于cpu执行。而这个过程需要调用其他语言的接口 本地库接口来实现整个程序的功能
运行时数据区组成部分
- 方法区(Method Area):存储类信息、常量、静态变量等。
- 堆(Heap):存储对象实例。
- Java栈(Java Stack):存储局部变量、操作数栈、动态链接、方法出口等。
- 本地方法栈(Native Method Stack):为本地(Native)方法服务。
- 程序计数器(Program Counter Register):存储当前线程执行的字节码行号。
JVM堆的内存结构
JVM的双亲委派模型
Bootstrap ClassLoader,extension classloader还有application classloader三个加载器分别去加载不同作用范围的jar包。负责加载核心库中的文件,在java_home\lib\的jar包。extension classloader负责加载java_home\lib\ext下的包。
双亲委派就是按照类加载关系,逐层进行委派,当加载一个class文件的时候,会把这个class的查询和加载委派给父加载器去执行。如果父加载器无法执行,会自己进行加载
7. Springboot
7.1 Spring
Spring中事务失效的场景有哪些
- 异常捕获处理,自己处理了异常,没有抛出,解决:手动抛出
- 抛出检查异常,配置rollbackFor属性为Exception
- 非public方法导致的事务失效,改为public
什么是事务?
Spring容器的生命周期?
bean的生命周期
实例化(Instantiation)
当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一尚未初始化的依赖时,容器会调用createBean进行实例化。 对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean。
属性设置(populate)
处理Aware接口
实例化后的对象被封装在BeanWrapper对象中,Spring根据BeanDefinition中的信息以及通过BeanWrapper提供的设置属性的接口完成属性设置与依赖注入。
BeanPostProcessor前置处理
如果想对Bean进行一些自定义的前置处理,那么可以让Bean实现了BeanPostProcessor接口,那么将会调用postProcessBeforeInitializ(Object obj,String s)方法。
InitialzingBean
如果Bean实现了InitialzingBean接口,执行afterPropertiesSet()方法。
BeanPostProcessor后置处理
以上几个步骤完成后,Bean已经正确创建。
如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitiazation(Object obj,String s)方法,由于这个方法是在Bean初始化结束时调用,所以可以被应用于内存或缓存技术;
3、 初始化(Initialization)
4、 销毁(Destruction)
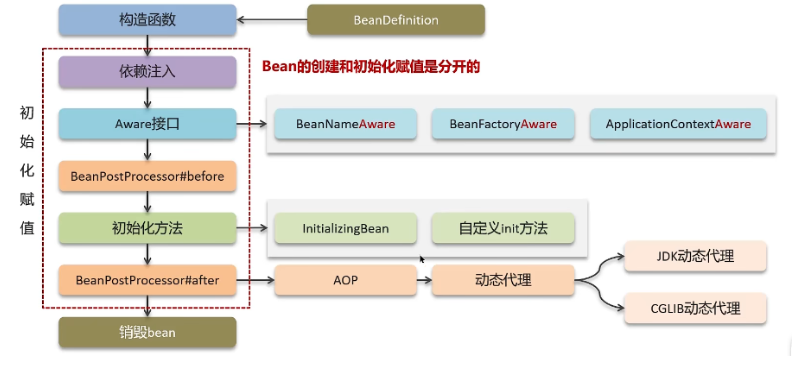
谈谈你对AOP的理解
面向切片编程,AOP主要作用是分离功能性需求和非功能性需求,使开发人员可以集中处理某一个关注点或者横切逻辑,减少对业务代码的侵入,增强代码的可读性和可维护性。Spring AOP 采用了两种混合的实现方式:JDK 动态代理和 CGLib 动态代理。
- 可以做接口日志记录
- 可以做事务管理
- 可以做接口的权限验证
- 可以做性能监测
常见的Spring注解
@Qualifier,@Autowired,@Required,@Configuration,@ComponentScan,@Lazy,@Value@Aspect
Spring里面的事务和分布式事务是如何区分的?
Spring并没有提供事务,它只是提供了对数据库事务的一个管理的封装。
我们可以通过声明式事务的配置,使得开发人员,可以从一些复杂的事务处理里面,去脱离出来,我们不需要关心连接的获取,事务的条件,事务的回滚这样一些操作。Spring里面的事务本质上是数据库的一个事务。
而分布式事务解决是的多个数据库事务操作的一个数据一致性问题。传统的数据库呢不支持跨库的事务操作。所以需要引入分布式事务的解决方案。
Spring并没有提供分布式事务的场景支持。不过我们可以使用一些主流的分布式事务的解决框架,比如seata.
继承到Spring生态里面。
Spring中的事务传播行为有哪些?
所谓事务传播行为,就是声明了多个事务的方法,相互调用的时候,这个事务应该如何去传递?
比如methodA()去methodB()都声明了事务,当调用methodB的时候,是开启了一个新 的事务,还是继续在methodA这个事务里面去执行。Spring有7种事务传播行为
required 默认。如果当前存在事务,就加入到这个事务里面去执行,如果不存在事务就新建一个事务
required_new 不管是否存在事务,都会新建一个事务去执行。新老事务之间是独立, 新事务抛出异常,并不会影响老事务的提交。
nested 如果存在事务,就嵌套在当前事务中去执行。如果当前没有事务。那就新建一个事务。
supports 表示支持当前的事务,如果当前不存在事务,就以非事务的方式执行。
not supports:以非事务的方式执行,如果当前存在事务,就需要把当前事务挂起来,
mendatory:一个强制性事务,如果当前不存在事务,就抛出一个异常
never:就是以非事务的方式来执行。如果当前存在事务则抛出异常。
@Condational的作用是什么?
@Condational的作用是给需要装载的Bean增加一个条件判断,只有满足条件Bean,才需要装载到IOC容器里面。这个自定义实现是我们可以自己实现的。
@Condational可以修饰在类或者方法上面。@Condational注解可以接受一个或多个实现了@Condational接口的类。它返回了一个boolean类型的matches方法。是用来实现Bean是否能被装载的判断逻辑
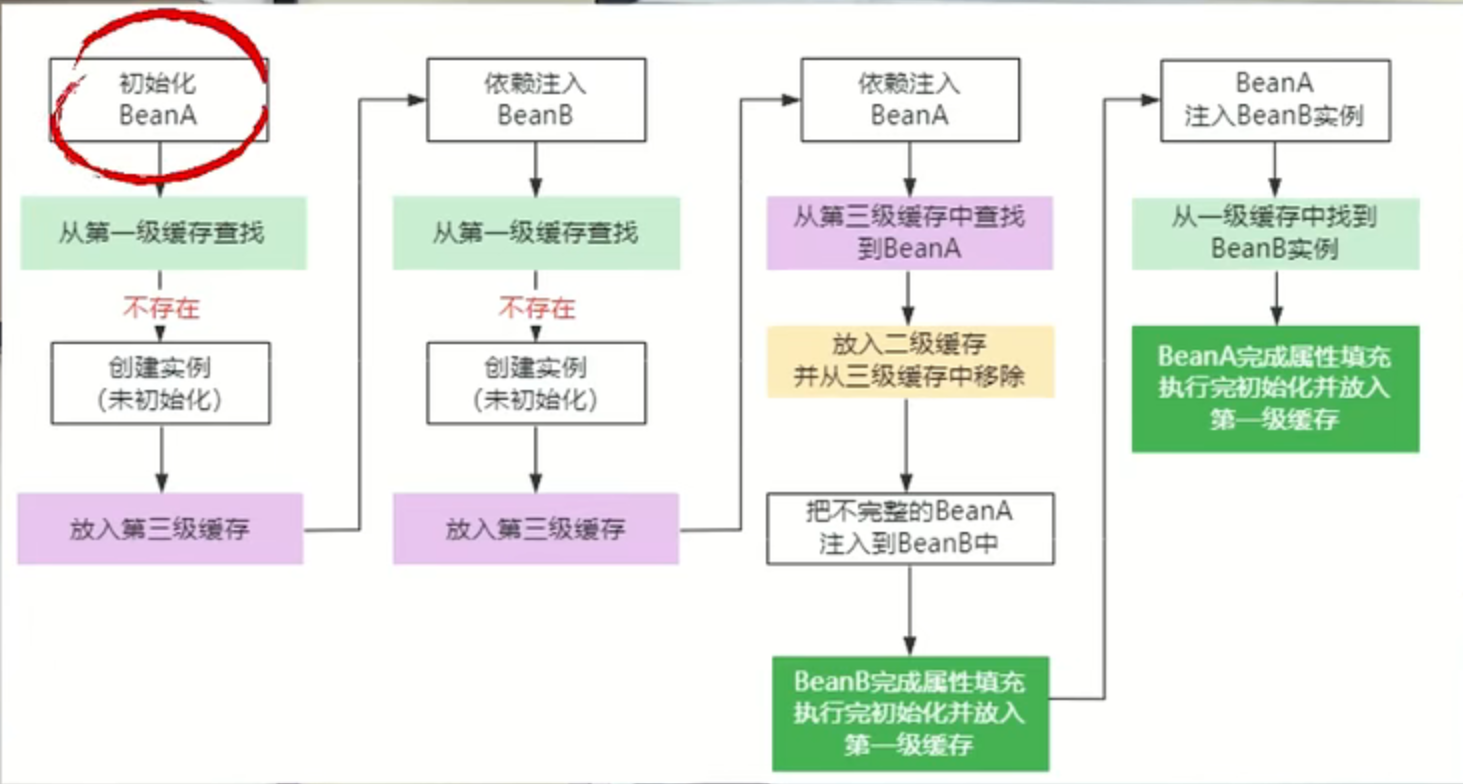
Spring是如何解决循环依赖的问题
一个或多个Bean之间会存在直接或间接的一个依赖关系,构成一个循环调用,第一种A依赖B,B依赖A。第二种,间接依赖,第三种是自我依赖,
所以Spring框架设计了三级缓存,第一级缓存里面存储完整的Bean实例,这些实例是可以被直接使用,第二级缓存里面存储的实例化以后,但是还没有设置属性值的Bean实例。也就是Bean里面的依赖注入还没有做,第三级缓存是用来存放Bean工厂的,它主要用来生成原始Bean对象,并放到第二级缓存里面。
Bean里面的实例化和Bean里面的依赖注入进行分离
过滤器和拦截器有什么区别?
- 运行是顺序不同,过滤器是Servlet收到请求之后,但是Servlet被调用之前运行的,拦截器是Servlet是在响应被发送到客户端之前来运行的。
- 配置方式不同。过滤器是在web.xml里面。拦截器是在Spring配置文件中配置。
- Filter依赖于Servlet容器,而Intercepter不依赖于Servlet容器
- Filter只能对request,response进行操作,而Intercepter能够对request,response,handler,modelandview,exception进行操作。
@Component和@Bean的区别?
@Component注解是一个通用注解,可以用于任何类上,包括普通的JAVA类,业务逻辑组件,持久化对象,通过Component注解,Spring会自动创建该类的实例注入到SpringIOC容器中。
@Bean注解用于配置类中声明一个Bean。把这个方法的返回对象注册到SpringIOC容器中。通过Bean注解,自定义Bean的创建和初始化过程,包括Bean的名称,作用域,依赖关系。
用途不同,@Component注解用于识别普通的类,@Bean是在配置类中声明和配置Bean对象的
使用方式不同,@Component注解是一个类级别的注解,Spring通过@ComponentScan注册扫描并注册为Bean的。@Bean是通过方法级别的注解使用,在配置类中手动声明和配置Bean
控制权限不同,@Component注解修饰的类是由Spring框架创建和完成初始化的
@Bean注解允许开发人员手动控制Bean的创建和配置过程。
构造函数注入和 setter 注入的区别?
- 实现方式不同:构造函数注入是通过构造函数将依赖对象注入进来,而setter注入是通过setter方法将依赖对象注入进来。
- 初始化顺序不同:构造函数注入是在对象创建时就完成了依赖注入,而setter注入可以在对象创建后任何时候完成依赖注入。
- 属性可变性不同:构造函数注入一般用于注入不可变的依赖对象,而setter注入用于注入可变的依赖对象。
- 程序员控制能力不同:构造函数注入不需要程序员主动调用setter方法来完成依赖注入,而setter注入需要程序员显式地调用setter方法来完成依赖注入。
- 可读性不同:构造函数注入可以让代码更加清晰明了,因为依赖注入是在对象创建时就完成了,而setter注入可能会让代码更加冗长和难以理解。
构造器:**适用场景:**当一个对象必须拥有某些依赖项才能正常工作时,构造器注入通常是更好的选择。如果依赖项是强制性的,且在对象的整个生命周期内不会发生变化,构造器注入是一种合适的方式。
Setter依赖注入:当对象的某些依赖项是可选的或者会在对象的生命周期内变化时,setter依赖注入可能更合适。如果对象的构造函数参数过多,而不是每次都需要提供全部参数,可以使用setter方法来逐步设置依赖项。
相同的两个id的bean会报错吗?
在同一个xml配置文件里面,不能存在id相同的两个bean.否则Spring容器在启动时会报错。因为id是bean里面的唯一标志符号,所以Spring在启动的时候回去验证id的唯一性。Spring解析xml文件解析成BeanDefinition阶段。
但是2个不同的配置文件里面,可以存在id相同的两个Bean。IOC在加载容器的时候会默认把多个相同id的Bean进行覆盖。
Spring3.0中出现@Configuration的配置类。如果存在多个名字相同的Bean,加载器只会注册第一个声明Bean的实例。
@Resource和@Autowired的区别
这两个注解都是Spring实现Bean的依赖注入的注解
- Autowired是默认根据类型来实现Bean的依赖注入。Autowired里面有一个required属性,默认值是true,表示强制要求bean实例的一个注入。如果Spring启动的时候,不存在对应类型的Bean。那么启动的时候就会报错。如果存在多个相同实例类型的Bean。就会报错,可以使用@Primary,@Qualifier这两个注解来实现。@Primary是优先装载这个Bean,而@qualifier是可以根据名字进行装载
- @Resource的jdk实现的注解。@Resource可以支持byName,和ByType两种注入方式。Spring会根据bean的名字取进行依赖注入,如果byType,Spring会根据类型来实现依赖注入。默认是name
BeaFactory和FactoryBean的区别
BeanFactory是所有Spring Bean容器的顶级接口,它为Spring容器定义了一套规范,并提供像getBean这样子的方法从容器中获取指定的Bean实例。
BeanFactory在生产Bean的同时,还提供了解决Bean之间的依赖注入的能力,也就是所谓的DI
FactoryBean是一个工厂Bean,它是一个接口,主要的功能呢动态地生产某一类型的Bean的实例。也就是我们自定义一个类型的Bean,并且加载到IOC容器中。有个重要的方法getObject()
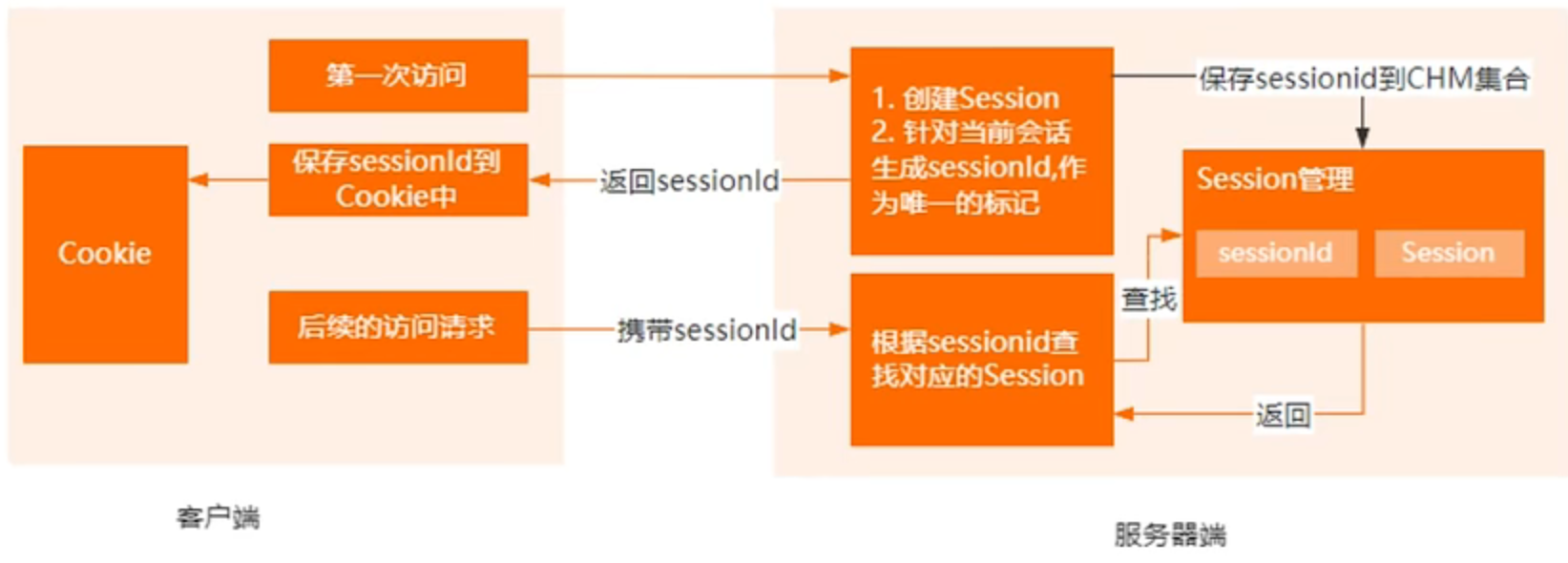
cookie和session之间的区别
cookie是客服端保存服务端数据的一种机制。当我们通过浏览器进行网页访问的时候,服务器可以把某一些状态数据,以key value的形式写入到cookie中,存储到客户端浏览器。客户端下次再进行访问的时候,我们可以携带这些状态数据,发送到服务器端,服务器端可以根据cookie中携带的内容,去识别使用者
session它表示一个会话,它是服务器端的一个容器对象,
默认情况下,它会针对每一个浏览器的请求,servlet容器都会分配一个session对象。session本质上我们可以认为它是一个concurrenthashmap.它可以存储当前产生的一些状态数据。我们都知道http协议本身是一个无状态协议。
服务器端并不知道客户端发送过来的多次请求是属于同一个用户的。session是用来弥补http无状态的一个不足。服务器端可以利用session来存储客户端在同一个会话里面的产生的多次请求的一个记录
为什么公司禁用@Transctional声明式事务
在方法上增加@Transctional声明式事务,如果存在多个长时间的任务,容易引发长事物问题。而长事物会带来锁的竞争,影响性能。导致数据库的连接池耗尽,影响程序的正常执行。
如果方法存在嵌套使用。嵌套方法也声明了@Transaction事务,出现了事务嵌套的调用行为。容易引起事务混乱。造成程序运行结果出现异常。
@Transctional声明式事务是将食物控制逻辑放在注解中的,会导致代码可读性和维护性下降。
会推荐编程式事务,灵活控制事务的范围,减少事务的锁定时间,提高 系统的性能。
Spring中哪些方式可以吧Bean注入到IOC容器
- 使用xml方式来声明bean的定义,Spring容器在启动的时候会加载并解析这个xml
- 使用@CompontScan注解来扫描声明了@Controller,@Service,@Component注解的类
- 使用@Configuration注解声明配置类,并使用@Bean注解实现Bean的定义,这种方式其实是xml方式的一种演变
- 使用@Import来导入一个bean
- 使用FactoryBean工厂bean,动态构建一个Bean实例
- 实现ImportBeanDefinitionRegistrar接口,可以动态注入Bean实例。
- 实现ImportSelector接口,动态批量注入配置类或者Bean对象,这个在SpringBoot里面的自动装配机制里面有用到
Spring的Bean作用域有哪些
Spring IOC是可以非常方便地管理实例的
Bean存在生命周期的,也就是所谓的作用域,常规的生命周期只有2种。
- 也就是单利,意味着整个Spring容器中只会存在一个Bean实例,
- Prototyoe原型,意味着每次从IOC容器去获取指定Bean的时候,都会返回一个新的实例对象。
但是基于Web场景下,增加了一个会话维度,来控制Bean的生命周期。
- 第一个是request,针对每一次http请求都会创建一个新的Bean
- 第二个是Session,以session会话为维度,同一个session共享同一个Bean实例不同的session产生不同的Bean实例
- 第三个是globalsession。针对全局session维度共享同一个Bean实例。
IOC的原理
在传统的Java程序开发里面,一般使用new来创建对象,这种方式会导致程序里对象的依赖关系比较复杂,而且耦合度较高,而IOC的作用就是实现了对象的管理
IOC就是控制反转,核心思想是把对象的创建,控制权限,交给Spring进行管理。如果想要获取某个实例,直接通过IOC获取即可。
Spring有很多方式进行bean的注册,比如xml标签bean,bean注解,配置类。spring在启动的时候会解析这些bean,创建实例保存在ioc容器中。
- 第一个阶段是ioc的初始化阶段。首先根据xml或者注解,生成一个Beandefinition。beandefinition实体有bean的名字,属性等信息。保存在一个map集合里然后注册到ioc容器中,完成初始化。
- 第二个阶段是对bean初始化和依赖注入。通过反射,对没有lazy-init属性的对象进行初始化,然后完成bean的依赖注入
- 最后一个阶段,就是bean的使用,通常使用 Autowired这样子的注解。Beanfactory.getbean()
DI依赖注入
DI就是依赖注入,通常由三种方式来描述依赖于依赖之间的关系。
接口注入,setter注入,构造器注入
基于构造器的注入和基于setter的注入有什么区别,应用场景是什么?
当一个类有多个依赖项,而不是所有的依赖项都是必须的时候,Setter注入是一个不错的选择。可以只注入那些需要的依赖项,而将其他依赖项保持为null或默认值。
构造器:必须依赖: 当一个类的依赖项是必须的,而且在对象创建时就需要将所有必须的依赖项传递进来时,使用构造器注入。
Spring Been如何保证并发安全
- 可以设置Bean的作用为原型,这样每次荣容器中获取该bean时,都会创建一个新的实例,避免多线程共享同一个对象实例的问题
- 在不改变Bean的作用于的情况下,可以避免在Bean中存在可变状态的声明。比如设置cocurrentmap等局部变量来保存可变状态
- 使用java并发编程中提供的同步锁机制来保证并发安全性
7.2 SpringMVC
谈谈你对Spring MVC的理解
在servlet的基础上构建的,并且使用了mvc模式,设计的web框架,目的是简化传统的servlet+jsp传统的web开发模式,springmvc架构设计是对java web里面的mvc框架模式做了一些增强和扩展,把传统的mvc框架里面的controller控制器,分成了前端控制器dispatcherservlet和后端控制器controller。把model模型拆分成业务层service和数据访问层repository。在视图层面,可以支持不同的视图,freemark,velocity ,jsp等
常见是SpringMVC注解
@Controller@RequestMapping@CookieValue@CrossOrigin@ExceptionHandler@InitBinder@MatrixVariable@PathVariable@RequestBody@RequestHeader@RequestParam@RequestPart@ResponseBody@ResponseStatus@ControllerAdvice@RestController@RestControllerAdvice@SessionAttribute@SessionAttributes
请你说说SpringMVC的执行流程
首先会将客户端的请求发送到dispatchservlet控制器中,dispatchservlet会将请求的url给handlermapping映射器进行处理,根据url匹配到相应的handlerexecutionchain处理器中。调用 处理器适配器handleradapter去执行处理器handler。执行结果并返回结果modelandview给前端控制器。视图解析器根据modelandview进行视图解析,把结果返回给View对象。View对象进行渲染,把结果返回给客户端。
7.3 Mybtais
Mybatis如何进行分页?
- 直接在select语句上增加数据库提供的分页关键字,然后在应用程序里面传递当前页,以及每页展示条数据
- Mybatis提供的rowBounds对象,实现内存级别分页。
- 基于Mybatis里面的interceptor拦截器,在select语句执行之前动态拼接分页关键字
Mybatis中的#{}和${}的区别是什么
都是动态的传递参数到xml里面,在传递以后呢,mybatis会对这两个占位符进行动态的解析,#{}等同于jdbc里面一个?号占位符。它相当于向preparedStatement的里面的预处理语句设置参数,而preparedStatement里面的SQL语句是预编译的。SQL语句使用了占位符规定了SQL语句的一个结构,并且在设置参数的时候,如果有特殊字符会自动进行转义。#{}可以防止SQL注入,${}占位符相当于直接把参数拼接到原始的SQL里面,Mybatis不会对它进行任何的特殊处理。
Mybatis里面的缓存机制
Mybatis设计二级缓存,来提升数据的一个检索效率,避免每一次检索数据都去查询数据库,一级缓存是sqlsession级别的一个缓存,叫做本地缓存,因为每一个用户在执行查询的时候,都使用sqlsesion去查询,mybatis把查询的数据缓存到sqlsessionb的本地缓存里。如果进行跨sqlsesion级别的缓存,一级的缓存是无法做法的,当多个用户进行查询,只要有任何一个sqlsession拿到了数据,就会放入到二级缓存里面,其他sqlsession就直接从二级缓存里面去加载数据。
一级缓存的sqlsession里面有一个executor。里面有一个localcache对象。当用户发起查询的时候,mybatis会根据查询语句在localcache里面寻找。
开启二级缓存之后,会被多个sqlsession共享,所以它是一个全局缓存,查询流程是先查二级缓存,再查一级缓存,最后查数据库。
Mybatis和mybatisplus优缺点
- MyBatis 提供了强大的灵活性,开发者可以完全控制 SQL 语句的编写和执行过程,适用于复杂的查询和特定数据库特性的使用。
- SQL 映射配置简单:MyBatis 使用 XML 或注解来配置 SQL 映射关系,使得 SQL 语句与 Java 代码分离,提高了可读性和维护性。
- 良好的性能:MyBatis 通过手动编写 SQL 语句和使用原生 JDBC 特性,可以针对性地进行性能优化和调整。此外,它还提供了一些缓存机制,可以减少数据库的访问次数,提高查询效率。
- 轻量级和简单易用:MyBatis 是一个相对轻量级的框架,它的学习曲线相对较低,容易上手和使用。它没有太多的依赖和复杂的配置,适合中小型项目的开发。
缺点:
- 手动编写 SQL 语句:MyBatis 需要开发者手动编写和维护 SQL 语句,对于复杂的查询或频繁的数据库操作,可能需要花费更多的时间和精力来编写和优化 SQL。
- 繁琐的配置文件:MyBatis 使用 XML 或注解来配置 SQL 映射关系,配置文件中可能存在大量的配置项和繁琐的语法,对于一些开发者来说,可能不够直观和简洁。
- 缺乏自动化代码生成:MyBatis 默认不提供自动化的代码生成工具,需要开发者手动编写实体类、Mapper 接口和 XML 配置文件。这在一些项目中可能需要一些重复性劳动和维护工作。
- 缺少全面的对象关系映射:MyBatis 是一种半自动的对象关系映射(ORM)框架,相对于全自动的 ORM 框架,如 Hibernate,它对于复杂的对象关系映射支持可能不够全面和便捷。
优点:
简化开发:MyBatis Plus 提供了更多的增强功能,如注解支持、代码生成器、Lambda 表达式、分页插件等。这些功能使得开发更加简洁和高效,减少了开发者的工作量和重复性劳动。
注解支持:MyBatis Plus 提供了更多的注解来简化 SQL 的编写,减少了对 XML 配置的依赖。通过使用注解,开发者可以直接在实体类上进行定义和配置,提高了代码的可读性和可维护性。
自动生成代码:MyBatis Plus 提供了代码生成器功能,可以根据数据库表结构自动生成实体类、Mapper 接口以及基础的 CRUD 方法。这大大减轻了开发者编写和维护这些代码的负担,提高了开发效率。
Lambda 表达式支持:MyBatis Plus 支持使用 Lambda 表达式进行条件查询,使得查询语句更加简洁和易读。这种功能提供了一种更加优雅的方式来构建复杂的查询条件。
分页插件:MyBatis Plus 提供了方便的分页插件,可以轻松地进行分页查询操作,减少了手动编写分页逻辑的复杂性。
社区支持和活跃度:MyBatis Plus 在开源社区中具有较大的影响力和活跃度,拥有庞大的用户群体和相应的开发者支持。
缺点:可能过于依赖框架:使用 MyBatis Plus 可能会过度依赖框架本身,对于一些复杂的数据库操作或特殊需求,可能不够灵活和自由。
找不到mapper原因
springboot配置文件的书写问题: mapperLocations
xml文件在java文件中的mapper中和Mapper接口放在一起的,打包时候打包不上的问题
Mybatis-plus的配置
mapperLocations 扫描MyBatis Mapper 所对应的 XML 文件位置
typeHandlersPackage: TypeHandler 扫描路径,如果配置了该属性,SqlSessionFactoryBean 会把该包下面的类注册为对应的 TypeHandler,TypeHandler 通常用于自定义类型转换。
typeAliasesPackage:MyBaits 别名包扫描路径,通过该属性可以给包中的类注册别名,注册后在 Mapper 对应的 XML 文件中可以直接使用类名,而不用使用全限定的类名(即 XML 中调用的时候不用包含包名)。
typeEnumsPackage:枚举类 扫描路径,如果配置了该属性,会将路径下的枚举类进行注入,让实体类字段能够简单快捷的使用枚举属性。
7.4 SpringBoot
SpringBoot自动装配机制
@SpringBootApplication注解是一个复合型的注解,真正实现装配的注解是@EnableAutoCOnfiguration这个注解,主要依靠三个核心的关键技术
引入starter,启动依赖主键的时候,必要要包含一个@Configuration配置类。而我们需要通过@Bean这个注解,声明需要装配到IOC容器里面的Bean对象。这个配置类是放在第三方的jar里面的,然后使用SpringBoot约定优于配置的这个理念,去把路径放在了classpath:/META-INF/Spring.factories文件里面,这样子SpringBoot第三方jar配置类的位置。主要使用SpringFactoriesLoader来完成的
SpringBoot拿到第三方jar包的配置类后,在通过Spring提供的importSelector接口,来实现这些配置类的动态加载。从而完成自动装配的动作。
SpringBoot的新特性
8. 分布式
如何保证消息的高效读写?
- 零拷贝: kafka和RocketMQ都是通过零拷贝技术来优化文件读写
- 传统文件复制方式:需要对文性在内存中进行四次拷贝。
- 零拷贝:有两种方式,mmap和ltansfile,Java当中对零拷贝进行了封装,Mmap方式通过MappedByteBuffer对象进行操作,而transfie通过rleChannel来进行操作。Mmap适合比较小的文件,通常文件大小不要超过1.5G ~2G之间。Transtile没有文件大小限制。RocketMQ当中使用Mmap方式来对他的文件进行读写. 在kafika当中,他的index日志文件也是通过mmap的方式来读写的。在其他日志文件当中,并没有使用零拷贝的方式。Kalka使用transtile方式将硬盘数据加载到网卡。
SOA、分布式、微服务之间有什么关系和区别?
- 分布式架构是指将单体架构中的各个部分拆分,然后部署不同的机器或进程中去,SOA和微服务基本上都是分布式架构的
- SOA是一种面向服务的架构,系统的所有服务都注册在总线上,当调用服务时,从总线上查找服务信息,然后调用
- 微服务是一种更彻底的面向服务的架构,将系统中各个功能个体抽成一个个小的应用程序,基本保持一个应用对应的一个服务的架构
怎么拆分微服务?
拆分微服务的时候,为了尽量保证微服务的稳定,会有一些基本的准则;
1.微服务之间尽量不要有业务交叉。
2.微服务之前只能通过接口进行服务调用,而不能绕过接口直接访问对方的数据。
3.高内聚,低耦合。
怎样设计出高内聚、低耦合的微服务?
高内聚低耦合,是一种从上而下指导微服务设计的方法。实现高内聚低耦合的工具主要有同步的接口调用和异步的事件驱动两种方式.
有没有了解过DDD领域驱动设计?
什么是DDD:在2004年,由EricEvans提出了,DDD是面对软件复杂之道,Domain-DIven-Design -Tackling Complexity in the Heart of Software大泥团:不利于微服务的拆分。大泥团结构拆分出来的微服务依然是泥团机构,当服务业务逐渐复杂,这个泥团又会膨胀成为大泥团。DDD只是一种方法论,没有一个稳定的技术框架。DDD要求领域是跟技术无关、跟存储无关、跟通信无关。
你的项目中是怎么保证微服务敏捷开发的?
- 开发运维一体化。
- 敏捷开发:目的就是为了提高团队的交付效率,快速迭代,快速试错
- 每个月固定发布新版本,以分支的形式保存到代码仓库中。快速入职。任务面板、站立会议。团队人员灵活流动,同时形成各个专家代表
- 测试环境-生产环境-开发测试环境SIT-集成测试环境-压测环境STR-预投产环境-生产环境PRD
负载均衡策略
- 轮询策略 轮询策略是最简单且常见的负载均衡策略之一。它将请求按照顺序依次分发给后端服务器,实现了请求均匀地分配到每个服务器上。该策略适用于后端服务器性能相近且负载相对平衡的情况。然而,当某个服务器负载过高或者响应速度较慢时,轮询策略无法根据实际情况进行动态调整,可能导致请求分发不均衡的问题。
- 加权轮询策略 为了解决轮询策略的不足,加权轮询策略引入了权重的概念。每个后端服务器都被赋予一个权重值,权重越高的服务器能够处理的请求越多。这样可以根据服务器的性能和负载情况,动态地调整权重值,使得负载分配更加合理。加权轮询策略适用于后端服务器性能不均衡或者负载波动较大的情况。
- 最少连接策略 最少连接策略是根据后端服务器的连接数来进行负载均衡的策略。该策略将请求分发给当前连接数最少的服务器,以确保服务器的负载均衡。最少连接策略适用于处理长连接请求,能够更好地利用服务器资源。然而当服务器的处理能力不均衡时,可能导致某些服务器的连接数过高,从而影响整体的负载均衡效果。
- IP哈希策略 IP哈希策略是根据客户端的IP地址进行负载均衡的策略。它将相同IP地址的请求分发到同一个后端服务器上,以保证同一客户端的请求都被同一个服务器处理。这种策略可以确保与特定客户端的会话信息保存在同一个服务器上,适用于需要保持会话一致性的应用场景。然而,当客户端数量较少或者IP地址分布不均匀时,IP哈希策略可能导致负载不均衡的问题。
- 动态负载策略 动态负载策略是根据服务器的实时负载情况进行动态调整的策略。通过实时监测服务器的性能指标,如CPU使用率、内存占用率等,可以根据具体情况进行负载均衡的决策。例如,当某个服务器负载过高时,动态负载策略可以将请求分发给负载较低的服务器,以实现负载均衡。动态负载策略能够根据实际情况自动调整,适用于负载波动较大或者服务器性能不均衡的场景。
SpringCloud有哪些组件?
- Eureka:服务注册和发现组件
- Hystrix:熔断组件
- Ribbon:负载均衡组件
- Zuul,gateway:路由网关
Spring官方推出来的一套微服务解决方案,Springcloud是Spring官方针对各种出现的技术场景,定义的一套标准的规范。gateway实现应用网关,nacos实现服务注册与发现,ribbon实现负载均衡,hystrix实现服务熔断
为什么nacos有两种心跳机制?
对于临时实例,健康检查失败,则直接删除。这种特性适合于需要应对流量突增的场景,服务可以弹性扩容,当流量过去后,服务停掉即可自动注销。
对于持久化实例,健康检查失败,会设置为不健康状态。它的优点就是可以实时的监控到实例的健康状态,便于后续的告警和扩容等一系列处理。
Nacos实现原理?
注册中和配置中心的核心原理,信息的同步主要的几种方式:
- push (服务端主动push)
- pull (客户端的轮询), 超时时间比较短
- long pull (超时时间比较长)
微服务和分布式区别?
- 微服务(Microservices): 微服务是一种软件架构风格,它将一个大型的、复杂的应用程序拆分成一组小型、独立的、可独立部署的服务。这些服务通常围绕业务功能进行划分,每个服务负责一个特定的功能。服务之间通过轻量级的通信协议(如HTTP/REST、gRPC等)进行交互。微服务架构的目的是提高系统的可扩展性、灵活性和容错能力,降低各个服务之间的耦合度,使得开发、部署和维护更加容易。
- 分布式系统(Distributed Systems): 分布式系统是指一组独立的计算节点(如服务器、计算机等),通过网络互相通信、协作来完成共同的任务。分布式系统的目标是实现高可用性、可扩展性、容错性和负载均衡。在分布式系统中,各个节点可以运行不同的服务或应用,它们可以是同构的(运行相同的服务)或异构的(运行不同的服务)。
区别:
- 微服务是一种软件架构风格,关注的是如何将一个大型应用程序拆分成多个独立的、可独立部署的服务。而分布式系统是一种系统架构,关注的是如何在多个计算节点上协同工作,实现高可用性、可扩展性和容错性。
- 微服务架构可以是分布式系统的一部分,但并非所有分布式系统都采用微服务架构。微服务架构的系统通常是分布式的,因为各个服务可以部署在不同的计算节点上。然而,分布式系统可以采用其他架构风格,如单体应用、服务导向架构(SOA)等。
- 微服务关注的是服务的拆分和解耦,以提高系统的灵活性和可维护性。分布式系统关注的是在多个计算节点上实现高可用性、可扩展性和容错性。
什么是微服务?说一下你对微服务的理解
微服务是一种架构风格,我们可以把应用程序划分成小型的,松散耦合的服务。每个程序并通过轻量级的通信机制进行通信。每个服务都能进行独立部署,独立扩展,独立更新。提高了每个服务的可伸缩性,可维护性,可测试性。
集群
集群是指将多台服务器集中在一起,每台服务器都实现相同的业务,做相同的事情。
但是每台服务器并不是缺一不可,存在的作用主要是缓解并发压力和单点故障转移问题。我们可以利用一些廉价的符合工业标准的硬件构造高扩展、高性能、低成本、高可用的系统。
集群主要具有以下特性:
- 伸缩性(Scalability):一组服务器组在一起,像单个服务器一样分担处理一个繁重的任务,我们只需要将新的服务器加入集群中即可;
- 高可用性(High availability):集群的出现就是为了使集群的整体服务尽可能可用,以便考虑计算硬件和软件的易错性,避免单点失效发生;
- 负载均衡(Load balancing):均衡的应用程序处理负载或网络流量负载,使负载可以在计算机集群中尽可能平均地分摊处理。
- 高性能 (High Performance):并行计算(或称平行计算)是相对于串行计算来说的,并行计算能力的目的是用来提高计算速度。
什么是服务网格?
服务网格,也就是service mesh。是专门来处理服务端通信的一个基础设施层。
主要是去处理服务之间的一个通信的,并且负责实现请求的可靠性传递的,服务网格通常称为第三代微服务架构。当我们把一个电商系统进行微服务的形式去进行拆分以后,这些服务基本都是会部署到docker容器里面,或者kubernetes集群里面。由于每个服务的业务逻辑是独立的。每个服务必须要只要对方的通信地址,当有新的服务进来的时候,还需要对这些通信地址进行动态的维护。
所有服务的注册,容错,重试,安全,都是保证服务之间通信的一个可靠性。
被进一步的从一个sdk演进到了一个独立的代理进程sidecar。sidecar主要复杂各个微服务之间的一个通信。
承载了服务发现,调用容错,服务治理。使得微服务的基础能力和业务逻辑实现彻底的解耦。
典型的istio,它是由google开源的一个service mesh框架
服务发现是AP还是CP?
无论什么情况下,应用都能正常从注册中心获取到目标服务的通信地址。当注册中心不可用的时候,不能影响到服务之间的正常通信。注册中心应该是一个AP模型。
注册中心的地址感知,本身就存在延迟,所以设计一个cp模型的架构意义不大。
数据一致性模型有哪些
- 强一致性:当更新操作完成之后,任何多个后续进程的访问都会返回最新的更新过的值,这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据CAP理论,这种实现需要牺牲可用性。 入
- 弱一致性:系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。用户读到某一操作对系统数据的更新需要一段时间,我们称这段时间为“不一致性窗口”。
- 最终一致性:最终一致性是弱一致性的特例,强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。到达最终一致性的时间,就是不一致窗口时间,在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。最终一致性模型根据其提供的不同保证可以划分为更多的模型,包括因果一致性和会话一致性等。
分布式ID是什么?有哪些解决方案?
在开发中,我们通常会需要一个唯一D来标识数据,如果是单体架构,我们可以通过数据库的主键,或直接在内存中维护一个自增数字来作为D都是可以的,但对于一个分布式系统,就会有可能会出现ID冲突,此时有以下解决方案:
- uuid,这种方案复杂度最低,但是会影响存储空间和性能
- 利用单机数据库的自增主键,作为分布式ID的生成器,复杂度适中,ID长度较之uid更短,但是受到单机数据库性能的限制,并发量大的时候,此方案也不是最优方案
- 利用redis、 zookeeper的特性来生成id,比如redis的自增命令、zookeeper的顺序节点,这种方案和单机数据库(mysal)相比,性能有所提高,可以适当选用
- 雪花算法,一切问题如果能直接用算法解决,那就是最合适的,利用雪花算法也可以生成分布式D,底层原理就是通过某台机器在某一毫秒内对某一个数字自增,这种 方案也能保证分布式架构中的系统id唯一,但是只能保证趋势递增。业界存在tinyid、leaf等开源中间件实现了雪花算法
什么是CAP?
c是一致性?
访问分布式系统重的每一个节点都能获得最新的数据,
可用性,每次你请求都能获得一个有效的访问,但不保证数据是最新的。
分区容错性,对通信耗时的要求。
Nacos配置更新的工作流程
- Nacos采用的是一个长轮询的方式,向Nacos server端去发起配置更新,查询的这样一个功能。所谓长轮询,是客户端发起一次轮训请求到服务器端,当服务器端没有任何配置更新的时候,这个链接会一直打开。知道有配置更新或者链接超时之后返回。
- Nacos Client需要去获取服务器端变更的一个配置需要拿客户端本地的配置信息和服务端配置信息进行一个比较,一旦发现和服务端的配置有差异,就表示服务器配置有更新,需要把更新的配置拉到本地。但是由于配置数量多,导致配置效率地下,所以做了2个方面的优化
- 减少网络通信的数据量。客户端把需要比较的配置进行分片,每一个分片大小是3000。每一次最多拿3000个配置去nacos server端进行比较。分阶段进行比较和更新。
- 分阶段进行比较和更新,客户端把这3000个配置的key以及对应的value值的md5拼接成一个字符串,然后发送到Nacos Server端进行判断,服务端会逐个比较这些配置中md5不同的key,把存在更新的key返回给客户端。客户端拿到这些变更的key,循环逐个调用服务单获取这些key和value值
9. MySQL
innodb有哪些锁、基于什么加锁、不用索引场景下的锁粒度,和实现没有任何关系
什么是索引下推
定位慢查询
出现的问题
- 聚合查询
- 多表查询
- 表数据量过大查询深度分页查询
- 表象:页面加载过慢、接口压测响应时间过长(超过1s)
方案一:
开源工具调试工具: Arthas 运维工具:Prometheus 、 skywalking
方案二:
MySQL自带慢日志慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
mysql慢查询优化
利用慢查询日志定位慢查询 SQL
MySQL 提供了一个功能——慢查询日志,会记录查询时间超过指定时间阈值的 SQL 到日志中,便于我们定位慢查询并且优化对应的 SQL 语句。
- long_query_time,慢查询的时间阈值,单位秒,如果一个 SQL 语句的执行时间超过这个值,那么 MySQL 就认定其为慢查询
- slow_query_log,慢查询日志功能是否开启,默认关闭,开启后记录慢查询
- slow_query_log_file,慢查询日志文件的存储位置
通过 explain 分析慢查询 SQL
- select_type 表示查询语句的查询类型,包括简单查询、子查询等等
- table 表示查询的表,不一定是存在表,可能是本次查询中得到的临时表
- type 表示检索类型,使用全表扫描、还是索引扫描等
- possible_keys表示可能使用的索引列
- keys表示查询中实际使用的索引列,由查询优化器决定
修改 SQL,尽量让 SQL 走索引
MySQL的乐观锁和悲观锁?
悲观锁(Pessimistic Lock):就是很悲观,每次去取数据的时候都认为别人会去修改,所以每次在取数据的时候都会给它上锁,悲观并发控制实际上是 “先取锁,再访问” 的保守策略。mysql的悲观锁一般在插入,修改的时候会自动添加。也可以手动添加。一般使用SELECT ... FOR UPDATE或使用LOCK IN SHARE MODE语句来加锁。
MySQL一个查询执行的过程?
Mysql什么时候加锁?
- 原则 1:加锁的基本单位是 next-key lock。希望你还记得,next-key lock 是前开后闭区间。
- 原则 2:查找过程中访问到的对象才会加锁。
- 优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
- 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
- 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
MySql三范式
第一范式主要是确保数据表中每个字段的值必须具有
原子性,也就是说数据表中每个字段的值为不可再次拆分的最小数据单位。第二范式要求,在满足第一范式的基础上,还要**满足数据表里的每一条数据记录,都是可唯一标识的。而且所有非主键字段,都必须完全依赖主键,不能只依赖主键的一部分。**如果知道主键的所有属性的值,就可以检索到任何元组(行)的任何属性的任何值。
第三范式是在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关,也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段。
数据库为什么不用自增id?
数据表复制与合并在实际开发中,有时候需要将两个数据表进行合并或复制,如果这两个表中都有自增id,就会出现主键冲突的问题,导致数据表无法正常操作。分布式系统在分布式系统中,每个节点都可能有自己的自增id,这样在合并数据时就会出现相同的自增id,导致数据冲突。因此,在分布式系统中使用自增id作为主键并不是一个好选择。相反,使用全局唯一标识符作为主键可以避免这一问题。易受攻击使用自增id作为主键会暴露大量的信息。攻击者可以通过系统的自增id,推算出表中数据的总量、时间戳等信息。如果这些信息对系统安全有影响,就不建议使用自增id了。缺点
性能使用自增id当然会更快,因为自增id只需要查询当前表中最大的自增id,然后加1即可。而使用UUID或GUID需要进行更耗时的操作,以确保所生成的ID是全局唯一的。因此,如果系统对性能要求较高,就需要进行权衡和选择。
可读性使用自增id作为主键的可读性较好,可以很方便地显示出表中数据的增长情况。相比之下,UUID或GUID生成的主键具有较低的可读性,难以对表进行快速的查询。
MySql的主从同步原理
主库更新事件,比如说update,insert,delete等事件记录到binlog中
从库发起连接,连接到主库
主库创建一个binlog dump thread把binlog的内容发送到从库。
从库启动后会创建一个IO线程,读取主库传过来的binlog内容并写入到relay log
从库创建一个SQL线程,从relay log里面读取内容,从exec_master_log pos位置开始执行读取到的更新事件,将更新内容写入到从库里面。
主从数据同步设计到网络数据的传输,由于网络通信的延迟以及从库数据处理的效率问题,主从数据库同步延迟的一个情况
- 设计一主多从的方式来分担从库的压力,减少主从同步延迟的一个问题
- 如果对数据一次性要求较高,那么在从库存在延迟的情况下,可以强制走主库查询数据
- 可以从从库上执行 show slave status命令,获取seconds_behind_master字段的延迟时间。然后通过sleep阻塞等待固定时间后再次查询。
- 最后可以通过并行复制解决从库复制延迟的问题
mysql update是行锁还是表锁?
update到底是行锁,还是表锁。取决于update语句的条件
如果update的where条件包含了索引列,并且只更新一条数据。就会加行锁。
如果where条件中不包含索引类,就会加表锁
根据查询范围不同,mysql也会选择不同粒度的锁。
针对主键索引的for update操作。mysql会增加一个next-key lock锁
针对索引区间的查询或者修改,mysql会自动对索引加间隙锁。
什么是行锁和临键锁,间歇锁?
行锁,临键锁和间歇锁都是Mysql里面的innodb引擎去解决事务隔离性的一系列排他锁、
行锁也称为记录锁,当我们针对组件或者唯一索引加锁的时候,mysql默认会对这一行数据进行加锁,
间歇锁就是锁定一个索引区间,索引是用B+树进行存储的,默认会存在一个区间。默认锁定一个左右开区间的一个范围。在进行范围性查询的时候,无论是否是唯一索引,都会触发一个间隙锁。
临键锁是行锁+间隙锁。它锁定的范围即是一个索引记录,也包含了一个索引区间。会锁定一个左开右闭的一个区间。
最终是为了解决幻读这一问题。
Mysql的ACID
atomicity原子性,一个事务(transaction)中所有操作,要么全部完成,要么全部不成功,不会结束再某一个环节。事务执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态
consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度,串联型。
isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以方式多个事务并发执行由于交叉执行而导致数据的不一致。
durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
Mysql索引的优点和缺点?
索引是一种个能够去帮助mysql高效的去从磁盘去检索数据的一种数据结构。在Mysql的Innnodb引擎里面呢,采用的是B+树的结构去实现索引和数据存储。
通过B+树的结构来存储数据,可以大大减少数据检索时的磁盘IO次数,从而提升数据查询的性能。
B+树索引在进行范围查找的时候,只需要找到起始节点,然后基于叶子节点的链表结构往下读取即可提高查询效率。
通过唯一索引约束,可以保证数据表中每一行数据的唯一性。
当索引使用不规范的时候,会带来很多缺点
数据的增加,修改,删除,需要设计到索引的维护,当数据量较大的情况下,索引的维护会带来较大的性能开销。
一个表中允许存在一个聚簇索引和多个非聚簇索引,但是索引树不能创建太多,否则造成的索引维护成本太高。
创建索引的时候,需要考虑到索引字段值的分散性,如果字段的重复数据太多,创建索引反而会带来性能降低。
数据库连接池的作用?
数据库的连接池是一种池化技术,池化技术的核心思想就是实现资源的一个复用,避免资源的重复创建和销毁,带来的一个开销。在数据库这样子的应用程序,每一次向数据库发起crud操作的时候,都需要创建连接。而在数据库访问量比较大的情况下, 平凡地创建连接会带来比较大的性能开销,连接池的作用,就是提前初始化一些连接保存在连接池里面。当应用程序需要用到连接去进行数据操作的时候,直接去连接池里面取出一个已经建立好的链接。连接池的建立避免了每一次;连接的建立和释放。减少开销
连接池的参数:初始化连接数量,表示启动的时候初始化多少个连接保存到连接池里面
最大连接数:表示同时最多支持多个连接,如果连接数不够,后续要获取连接的线程会阻塞。
最大空闲连接数,表示没有请求的时候,连接池中要保留的最大空闲连接
最小空闲连接数,表示当连接数小于这个值的时候,连接池需要创建连接来补充到这个值。使用的时候一些参数
最大等待时间,就是连接池里面的连接用完了以后,新的请求要等待的时间,超过这个时间就会提示超时异常。
无效链接清除,清理连接池里面的无效链接,避免使用这个连接操作的时候出现错误。
Mysql的事务的实现原理?
Mysql里面的事务,满足acid特性,就是innodb如何满足acid这样一个特性。
首先是autometic原子性,保证事务要么成功,要么失败。如果失败就需要一个undo_log表,在事务执行的过程中,把修改之前的快照数据。
c就是一致性的,数据的完整性约束没有被破坏,这个更多依赖业务层面的保障,数据库提供像主键的唯一性约束,字段长度和类型的一些保障。
i表示事务的隔离性,多个事务对数据进行操作的时候,如何去避免多个事务的干扰。导致数据混乱的一个问题。innodb实现了sql92的标准,提供了四种隔离级别的一个实现。RU,RC,RR,Serializable(串行化)
innodb默认隔离级别是RR,MVCC机制解决了脏读和不可重复读的问题。使用行锁,和表锁来解决幻读的问题。
d表示事务的持久性,只要事务提交成功,那么对于这个数据的结果的影响是永久的,不能因为数据库宕机或者其他原因,导致数据变更的一个失效。理论上来说,事务提交过后直接进行刷盘就可以了,但是进行随机IO的效率实在太低。所以innodb使用buffer pool缓冲区来进行优化,数据更新的时候,先更新内存缓冲区。可能存在数据宕机,导致持久化失败的操作。无法满足持久化的操作。所以innodb引入了redo log文件
Mysql 四大日志
错误日志:默认存放位置/var/log/ 默认文件名字为mysqld.log
二进制日志(binlog)。记录所有ddl和dml语句,但是不包含数据查询语句作用:灾难时数据恢复,Mysql的主从复制。
查询日志:查询日志中记录了客户端是所有操作语句,
慢日志:慢查询日志记录了所有执行时间超过参数long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志
回滚日志(undo log):redo log是InnoDB引擎特有的:binlog是MySQL的Service层实现的,所有的引擎都可以使用。redo log是物理日志,记录的是在某一个数据页面上做了什么修改
Mysql 中binlog和redo log日志区别
使用场景不同:binlog主要用来做数据备份,数据恢复,数据同步。
redolog主要是在mysql数据库事务的ACID特性里面,用来保证数据的持久化特性的。比如数据崩溃时,可以通过redolog 来恢复未完成的数据,保证数据的完成性。redolog 可以把未提交的事务回滚,已提交的事务持久化。
记录信息不同:
binlog是记录数据库的逻辑变化。
redolog记录是物理的变化,也就是数据页变换的结果
可以合理的配置redo log的大小和数量,优化mysql的性能
记录的时机不同
binlog是在执行数据语句的时候,在主线程生成逻辑变化,是语句级别的记录方式。
redolog是innodb存储引擎层面的操作,是在mysql后台线程中去生成的。是事务级别的记录方式。
Mysql binlog三种模式
statement 模式 statement 模式记录的是 SQL 语句。 优点:日志量较小,占用空间小。执行速度快,因为只需要记录 SQL 语句即可。 缺点:对于使用了函数或随机数的 SQL 语句,可能会出现不一致的情况,比如随机数每次生成的都不一样。 因此,使用了函数或随机数的场景下,不建议使用 statement 模式。
row 模式 row 模式记录的是数据行的变化情况。 优点:对于使用了函数或随机数的 SQL 语句,不会出现不一致的情况。 缺点:日志量较大,占用空间较大。执行速度较慢,因为需要记录每一条数据的变化情况。
mixed 模式 mixed 模式是 statement 模式和 row 模式的混合模式,它能够根据具体的情况自动选择使用哪种模式。
优点:能够根据具体情况自动选择使用最优的模式。 缺点:执行速度较慢,因为需要根据具体情况选择使用不同的模式。
Mysql二阶段提交概念
Mysql开启了binlog日志的情况下,需要同时完成redolog和binlog的事务写入,binlog是一个是事务日志,redolog是数据库变更的逻辑日志,这是2个独立的写入磁盘的操作,并且两个操作都要成功。而为了保证两个日志内容的一致性,需要使用2阶段提交机制。把日志操作变成日志写入和日志提交两个阶段,来保证redolog和binlog写入的数据一致性。
第一阶段是prepare阶段,Mysql会将事务操作记录到redolog中并标记为prepare状态,
当事务提交时,mysql会将事务操作记录到binlog中,然后把redolog中的日志设置为commit状态。
为什么buffer pool里面有LRU算法?
buffer pool是空间换时间的思想,利用内存空间去缓存一些热点数据,从而去减少我们和磁盘的一个交互,从而提升性能。buffer pool是由三个部分组成,第一个是FreeList 空闲内存,第二个是LruList也就是一个内存淘汰算法,通过Lru算法保证内存的高效利用,避免一些非热点数据去占用我们的内存空间。第三个是flush list,里面存的脏页和一些修改后的数据。
为什么数据库字段建议设置为NOT NULL?
- 数据完整性,通过设置not null可以确保数据库中的数据完整性,在数据中出现不完整或不一致的情况
- 查询性能,数据库在查询的时候,不需要额外处理空值的情况,可以更加快速定位符合条件的数据行
- 开发的友好性。
日常工作中的优化sql
- 表结构和索引
- 为查询创建必要的索引。加索引是一种简单高效的手段,但是需要选择合适的列,同时避免导致索引失效的操作
- 分库分表
- 为表结构性选择格式的数据类型
- 读写分离
- 避免返回不必要的数据列,减少返回的数据列可以增加查询效率
- 根据explain或者profile查询分析器适当优化SQL结构,比如是否走全表扫描,避免子查询。
- Mysql参数的设置,设置buffer pool的策略。还有刷盘策略
- 硬件
如何解决幻读的问题?
脏读:是指一个事务处理过程中读取到了另一个未提交事务中的数据,导致两次两次查询结果不一致。
假设有两个事务 T0、T1。在 T1 中修改了数据,但还未提交事务,此时 T0 中读到修改后的数据。这就是“脏读”。如果 T1 再次修改数据,或者回滚了,那 T0 读到的数据就是脏的。
不可重复读:是指一个事务处理过程中读取了另一个事务中修改并已提交的数据,导致两次查询结果不一致。
假设有两个事务 T0、T1。在 T1 中修改了数据,但还未提交事务,此时 T0 中读到的仍是修改前的数据。
在 T1 提交了事务后,此时 T0 中读到的就是修改后的数据。这就是“不可重复读”。在 T0 事务开始到结束,读同一个数据,会读到不同的值。
幻读:事务A 按照一定条件进行数据读取, 期间事务B 插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B 新插入的数据称为幻读
隔离级别
读未提交(read uncommitted):一个事务还未提交时,它修改的数据都可以都被别的事务看到。三个问题一个也解决不了
读已提交(Read Cimmitted):一个事务提交之后,它修改的数据才会被别的事务。不存在脏读,可能存在不可重复读,幻读的问题
可重复读(Repeatable read) 一个事务执行中卡到的数据,总和事务开启事看到的数据是一致的,在可重复读的隔离级别下,未提交的事务对其他事务而是不可见的。
不存在脏读,不可重复读,但是存在幻读问题。
船型
什么是MVCC?
mvcc就是针对每个事务,生成一个事务版本,根据这个事务定制一个访问规则,然后通过undo的版本链来进行管理。
第一,一个事务只能看到第一次查询之间已经提交的事务已经当前事务的修改。一个事务不能看到当前事务第一次查询之后创建事务,已经未提交的事务修改。从而实现不同事务之间的数据隔离。
如果一个事务里存在当前读的一个问题,跳过了快照读,mvcc还是会存在幻读的问题。
LBCC来解决。
在亿级别的数据库中,怎么快速把uid=4的数据查出来
- 传统的索引查询可能会因为数据量过大,而变得效率低下,可以采取数据库分区,数据库分表。这是解决单数据库表数据量过大的常见方案,对id进行一致性hash取模运算。这样可以
- 使用搜索引擎,elasticsearch
- 数据的冷热分离。把热数据,存储在高性能的存储设备上(SSD),冷数据,存储在一般磁盘上
数据量达到多少的时候要进行分库分表
单表数据量,查询性能下降或者业务解耦
单表的数据量已经非常大,例如超过了百万级别,就需要考虑分表了。
数据库的性能,当单个数据的性能无法满足业务需求时,就需要考虑分库分表
如果某些表的数据访问频率非常高,单个数据库节点无法满足高并发的需求。
业务拆分,当系统的业务逻辑越来越复杂,不同的业务之间的数据耦合度越来越低,就需要考虑对系统进行拆分,以方便管理和扩展。
如何不顶机,进行数据迁移
把旧库的数据复制到新库中,而旧库中一直会有数据进行写的操作,所以我们还要进行同步的策略,我们需要一个同步的策略来实现新旧数据库的实时同步。这里我们可以采用一个双写的方案,在进行复制的同时,旧系统和新系统同时写入数据。保证两套系统同时进行。
什么是索引下推?什么是索引覆盖?什么是回表
一个表有且只有一个聚簇索引,但是可以存在多个非聚簇索引。当我们进行非聚簇索引查询的时候,如果返回的列不能满足查询结果列的需求的时候就需要从聚簇索引中获取行值。索引覆盖 sql语句中返回的结果列都在二级索引中都能找到,不需要回表。就叫索引覆盖。
高度为3的B+树可以存放多少数据
- 取决于索引的大小,数据页大小。B+树的每个节点都是一个数据页,非叶子节点都是索引值和页的偏移量。数据页默认大小是16KB。
- 假设一行数据大小是1k。一页就可以存放16条数据。主键类型bigint是8个字节,指针大小是6个字节。每个数据页的指针数量 16384/(8+6)=1170个指针。一个指针,指向存放记录页(16条数据)。一个高度为2的B+树大概能存放1170*16=18720条数据。
- B+树高度为3的时候,最高能存储千万级别的数据
分页查询 limit 500000,10和limit 10速度一样快吗?
limit 50000,10 表示从结果集中的第50000行开始,返回10条数据。
- 如果数据量不是太大的话,二者之间的速度差距不是很大。如果数据很大,limit 50000会跳过大量的数据行才能返回结果
- 如果有合适的索引,limit 50000,10可以通过索引直接定位到指定的行号返回结果,
- 总结果上看,limit 50000,10肯定会比limit 10速度慢一点
肯定得做数据层面优化,可以子查询的结果,作为过滤条件,
Mysql索引在什么情况下会失效?
- 没有使用索引列作为where子句的查询条件
- 对索引列做了函数操作,比如字符串操作,日期计算,Mysql没有办法在运行时,使用函数计算做索引匹配
- 对索引列进行类型转换。如果索引列是数字类型。而传入的数值是字符串,Mysql会默认对类型进行转换。
- like查询的查询字符串以通配符开头。Mysql在使用like进行查询时,且以通配符为开头,没有办法进行一个最左匹配、
- or 条件查询,当查询条件包含or条件时。如果or条件中的每个条件不涉及索引。
- 当查询条件设计到大量数据的时候。Mysql会认为索引意义不大。
为什么使用B+树而不使用B树
磁盘IO性能,查询性能,存储空间利用率
查询效率高,减少磁盘IO:首先B+树一个节点能够存储很多的值,导致树的深度不高,能够减少磁盘IO操作减少磁盘IO:B+树的非叶子节点存储索引,叶子节点存储数据信息。索引数据可以直接加载进内存中,然后进行范围和遍历时,通过一次磁盘读取就可以获得需要数据,减少IO操作。支持范围查询,排序,扫库等操作B+树能够更好进行范围查询,排序和全局扫描。对于B树而言,进行范围查询,需要遍历整个数才能获取所需要的数据。而B+数的数据都在叶子节点上,并且使用链表链接叶子节点。在做范围查询或排序时,直接遍历链表即可。B+树查询稳定,每次进行查询时,B+树的查询次数一样和IO次数都是一致的,而B树非叶子节点也存储数据。每次查询次数不一致。对于一个程序而言,稳定性很重要。
MyISAM和Mysql区别
- MyISAM是非事务安全的,而InnoDB是事务安全的
2、MyISAM锁的粒度是表级的,而InnoDB支持行级锁
3、MyISAM支持全文类型索引,而InnoDB不支持全文索引
4、MyISAM相对简单,效率上要优于InnoDB,小型应用可以考虑使用MyISAM
5、MyISAM表保存成文件形式,跨平台使用更加方便
6、MyISAM管理非事务表,提供高速存储和检索以及全文搜索能力,如果在应用中执行大量select操作可选择
7、InnoDB用于事务处理,具有ACID事务支持等特性,如果在应用中执行大量insert和update操作,可选择。
数据存储方式的不同,MyISAM里面的数据和索引是分开存储的,而Innodb是把数据和索引存储在同一个文件里面。
对于事务支持的不同,MyISAM不支持事务,InnoDB支持一个acid的事务处理
对于锁的支持不同,MyISAM只支持表锁,InnoDB支持行锁,间隙锁,临键锁,表锁
MyISAM不支持外键,InnoDB支持外键。
10. Redis
如何查询redis里面占用空间较大的key
使用redis-cli的命令行界面 redis-cli keys *
查看key的占用内存大小 redis-cli memory usage
RdbTools 工具查找大 key 使用 RdbTools 第三方开源工具,可以用来解析 Redis 快照(RDB)文件,找到其中的大 key。
Redis的大key怎么处理
在Redis中存储的某个key对应的value数据量很大的情况下有可能出现的问题已经解决方案?
- 把大key分割成多个小key来存储。把一个大的Hash结构分割成多个小的Hash结构。
- 搭建Redis Cluster集群,把key分配到不同的Hash slot槽所在的分片上。可以降低单个Redis的存储压力
- 如果已经存在了大Key,可以做数据的拆分和迁移
- 可以考虑压缩算法进行压缩,去减少压缩空间的占用
redis的哨兵机制
哨兵是 Redis 的一种运行模式,它专注于对 Redis 实例(主节点、从节点)运行状态的监控,并能够在主节点发生故障时通过一系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 系统的可用性。
- 监控:持续监控 master 、slave 是否处于预期工作状态。
- 自动切换主库:当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master。
- 通知:让 slave 执行 replicaof ,与新的 master 同步;并且通知客户端与新 master 建立连接。
五种类型,底层的实现
string ,hash,list,zset,set
分布式锁怎么实现?
SETNX + EXPIRE
但是使用这个方案要注意 setnx 与 expire 之间的原子性操作,如果在执行完 setnx 之后服务器 crash 或重启了导致加的这个锁没有设置过期时间,就会导致死锁的情况(别的线程就永远获取不到锁了)
SETNX + value 值(系统时间 + 过期时间)
把过期时间放在 setnx 的 value 里面,如果加锁失败,再拿出 value 值校验一下即可。
使用 Lua 脚本(包含 SETNX + EXPIPE 两条指令)
实际上,我们可以使用 Lua 脚本来保证原子性(包含 setnx 和 expire 两条指令)
Redisson框架
只要线程一加锁成功,就会启动一个
watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了

缓存穿透,缓存崩溃,缓存雪崩
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
使用布隆过滤器,缺点实现复杂,存在误判
缓存击穿:给某一个key设置了过期时间,但这个key刚好过期,有大量并发请求,会瞬间把mysql压垮
解决方案,加锁,设置
缓存雪崩:缓存雪崩是指同一时间大量的缓存key同时失效或者redis服务宕机。
解决方案,给不同的key设置不同随机的ttl。使用集群,添加限流策略。
redis一个key和value占用多少空间?
redis的key和string类型value限制均为512MB。
什么是是跳表?
跳表是可以实现二分查找的有序链表
- skiplist是一种以空间换取时间的结构。
- 由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找。
- 提取多层关键节点,就形成了跳跃表
跳表 = 链表 + 多级索引
跳跃表
主要有2个部分组成,第一个部分表头,它负责维护跳跃表的节点指针,
跳跃表的节点:保存着元素值以及多少层,
层的概念,保存着指向其他元素的指针,高层的指针会大于等于底层的指针,为了提高查询效率,程序总是先从高层开始去访问,随着元素的范围值的缩小,去慢慢降低层次。
表尾全部null指针,表示跳跃表的末尾。
跳表的查询过程是从最高处逐层像下查找的,每次查找,都是在当前层中找到小于目标元素的最大值,然后再跳转到下一层,继续进行查找,如果最后找到了目标元素,就返回这个元素所在的节点,所以跳跃表并没有直接跳跃两层索引的情况。
说说链表和数组的优缺点?为什么引出跳表?
跳表是一个最典型的空间换时间解决方案,而且只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的适用范围应该还是比较有限的
维护成本相对要高 - 新增或者删除时需要把所有索引都更新一遍; 最后在新增和删除的过程中的更新,时间复杂度也是O(log n)
Redis 支持多种数据数据类型,每种基本类型,可能对多种数据结构。什么时候,使用什么样数据结构,使用什么样编码,是redis设计者总结优化的结果。
- String:如果存储数字的话,是用int类型的编码;如果存储非数字,小于等于39字节的字符串,是embstr;大于39个字节,则是raw编码。
- List:如果列表的元素个数小于512个,列表每个元素的值都小于64字节(默认),使用ziplist编码,否则使用linkedlist编码
- Hash:哈希类型元素个数小于512个,所有值小于64字节的话,使用ziplist编码,否则使用hashtable编码。
- Set:如果集合中的元素都是整数且元素个数小于512个,使用intset编码,否则使用hashtable编码。
- Zset:当有序集合的元素个数小于128个,每个元素的值小于64字节时,使用ziplist编码,否则使用skiplist(跳跃表)编码
Redis中的哨兵机制算法
Redis里面的Master-Slave集群是不具备故障恢复能力的,Master节点出现故障,哨兵节点检测到以后,会从redis集群中国的slave节点中去选举出一个作为新的Master。具体的判断依据呢有两个部分,第一个部分是筛选,第二个部分是综合评估,
在筛选阶段会过滤掉不健康的节点,下线或者没有回复sentinel哨兵心跳相应的Slave节点。评估实例过往的网络连接情况,如果在一定时间内,Slave和Master经常性断链,而且超过一定的阈值也不会考虑。剩下就是健康节点,
评估,根据Slave优先级来判断,通过slave-priority配置项,可以给不同的从库设置不同优先级,优先级高的优先成为master
选择数据偏移量差距最小的节点,其实就是比较slave与原master复制进度差距,避免丢失过多数据的问题。
slave runID,在优先级和复制进度都相同的情况下,runID越小说明创建时间越早,优先选为master.
如果其他哨兵集团没有感知的话,需要使用共识算法来达成一致。这里用到了raft协议。
Redis key过期?为什么内存没释放?
Redis使用定期删除和惰性删除两种操作。
定期删除:Redis会每隔一端时间执行的一次定期删除操作,随机抽取一部分的key,检查时间是否过期,如果过期,则直接删除,并释放对应的内存空间。能够保证定期清理掉过期的key。
惰性删除是指当一个key被访问是,redis会检测key是否过期,过期则删除并释放相应的内存空间。
意味着Redis的key过期清理并不是实时的,
Redis Keys命令有什么问题?
Redis中的keys命令,用于返回匹配指定规则的所有键,类似于数据库里面like模糊匹配功能。
- 性能问题,keys命令需要遍历整个Redis的键空间。Redis中的key数量非常庞大,遍历过程非常耗时从而影响性能
- 阻塞问题,keys命令是一个阻塞命令,它会阻塞所有其他客户端对redis的访问,知道keys命令访问结束
请描述以下Redis中AOF 重写机制
AOF是Redis提供的数据持久化的一个方式,它里面采用了指令追加的一个方式,近乎适时的去实现数据指令的一个持久化,因为通过AOF这种方式,会把每一个数据更改的一个操作指令,追加并且存储到AOF文件里面。所以很容易导致AOF文件出现过大,造成IO性能的一个问题,
为了解决这个问题,Redis设计了一个AOF重写机制,把AOF文件里面的相同的指令进行压缩,只保留最新的一个数据操作指令,简单来说,假如AOF文件里面存储了某个key的多次变更记录,但是数据恢复的时候我们只需要最新的数据操作指令就可以了,历史文件就没意义必要占用空间。
- 首先,根据当前Redis内存里面的数据,重新构建一个新的AOF文件,
- 然后,读取当前Redis里面的数据,写入到新的AOF文件里面
- 最后重新完成以后,用新的AOF文件覆盖现有的AOF文件
由于AOF需要访问所有的key,value值,所以Redis使用后台进行AOF重写,为了保证数据一致性问题,主线程在重写的过程中需要把数据变化追加到AOF的重写缓冲区里面,等到AOF文件重写完成以后,在把AOF重写缓冲区里面的数据追加到新的AOF文件里面。
Redis存在线程安全问题吗?
Redis server本身是一个线程安全的k-v数据库,在redis server执行指令的时候,不需要任何的同步机制,不会存在任何的线程安全的问题。虽然redis 6增加了多线程模型。只是去处理网络的io事件,对于指令的执行过程,仍然采用主线程来处理的。
Redis Server本身可能出现的性能瓶颈点无非就是网络IO,CPU,内存。但是CPU并不是Redis瓶颈点,所以没有必要使用多线程来执行指令。
如果存在多个redis客户端同时执行多个指令的情况下呢,就无法保证原子性,尽可能使用redis里面的原子指令。对多个客户端的资源访问加锁,通过lua脚本来实现多个指令的操作。
Redis为啥这么快
- 基于内存实现
- 高效的数据结构
- 合理的数据编码
- IO多路复用
redis实现一个延时机制
延时队列一种特殊类型的消息队列,它允许把消息发送到队列中,但不立即投递给消费者,而是在一定时间后再讲消息投递给消费者。可以使用zset。
使用zadd方式把消息添加到sorted set中,并把当前时间作为score。
启动一个消费者线程,使用zrangebyscore命令获取定时从zset中获取当前时间之前的所有消息。
消费者处理完消息后,可以从有序集合中删除这些消息
这种方式一般消费者向redis进行轮训,轮训时间存在时间间隔,所以延时消息的实际消费时间会大于设定的时间
epoll和poll的区别
- select模型,使用的是数组来存储就socket连接文件描述符,容量是固定的,需要通过轮训来判断是否发生了IO事件
- poll模型,使用的是链表来存储socket连接文件描述符,容量是不固定的,同样需要通过轮训来判断是否发生了io事件
- epoll模型。epoll和poll是完全不同的,epoll是一种事件通知模型,当发生了IO事件时,应用程序才进行IO操作,不需要像poll模型那样主动去轮训。
Redis中的持久化机制的优缺点
rdb优点
- 体积更小:相同的数据量rdb数据比aof的小,因为rdb是紧凑型文件。
- 恢复更快:因为rdb是数据的快照,基本上就是数据的复制,不用重新读取再写入内存。
- 性能更高:父进程在保存rdb时候只需要fork一个子进程,无需父进程的进行其他io操作,也保证了服务器的性能。
rfb缺点
- 故障丢失:因为rdb是全量的,我们一般是使用shell脚本实现30分钟或者1小时或者每天对redis进行rdb备份,(注,也可以是用自带的策略),但是最少也要5分钟进行一次的备份,所以当服务死掉后,最少也要丢失5分钟的数据。
- 耐久性差:相对aof的异步策略来说,因为rdb的复制是全量的,即使是fork的子进程来进行备份,当数据量很大的时候对磁盘的消耗也是不可忽视的,尤其在访问量很高的时候,fork的时间也会延长,导致cpu吃紧,耐久性相对较差。
aof优点
- 数据保证:我们可以设置fsync策略,一般默认是everysec,也可以设置每次写入追加,所以即使服务死掉了,也最多丢失一秒数据
- 自动缩小:当aof文件大小到达一定程度的时候,后台会自动的去执行aof重写,此过程不会影响主进程,重写完成后,新的写入将会写到新的aof中,旧的就会被删除掉。但是此条如果拿出来对比rdb的话还是没有必要算成优点,只是官网显示成优点而已。
缺点
- 性能相对较差:它的操作模式决定了它会对redis的性能有所损耗。
- 体积相对更大:尽管是将aof文件重写了,但是毕竟是操作过程和操作结果仍然有很大的差别,体积也毋庸置疑的更大。
- 恢复速度更慢:AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
Redis和Mysql如何保证数据一致性?
Redis是实现应用和数据库之间的一个读操作的缓存层的,主要目的呢是去减少数据库的io操作。还可以提升数据的io性能。用户查询数据的时候一般会查询redis里面的数据,如果没有命中,则会进行mysql的查询。由于数据更新,会有一个顺序在里面,并不像mysql中的多表事务操作,可以满足acid的特性。
- 先更新数据库,再更新缓存,如果缓存更新失败,则和redis中的数据是不一致的。
- 先删除缓存,然后在进行更新数据库。
- 比如基于rabbitmq的可靠性信息通信进行更新
- 或者基于canel组件监控mysql中binlog日志,把更新后的数据同步到redis里面。这个得保证数据的短期一致性问题。
Redis 全量复制一遍发生在 slave 初始化阶段,这时 slave 需要将 master 上的所有数据都复制一份。具体步骤如下:
- slave 连接 master,发送 SYNC 命令;
- master 接收到 SYNC 命名后,开始执行 BGSAVE命令生成 RDB快照文件并使用缓冲区记录此后执行的所有写命令;
- master BGSAVE执行完后,向所有 slave 发送快照文件,并在发送期间继续记录被执行的写命令;
- slave 收到快照文件后丢弃所有旧数据,载入收到的快照;
- master 快照发送完毕后开始向 slave 发送缓冲区中的写命令;
- slave 完成对快照的载入,开始接收命令请求,并执行来自 master 缓冲区的写命令;

Redis 增量复制是指 slave 初始化后开始正常工作时 master 发生的写操作同步到 slave 的过程。
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset.如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
- 从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就获取从节点的offset值
- 主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步

11. RabbitMq
消息队列有哪些作用
解耦:使用消息队列来作为两个系统之间的通讯方式。两个系统不需要相互依赖了
异步:系统A给消息队列发送完消息之后,就可以继续做其他事情了
流量削峰:如果使用消息队列的方式来调用某个系统,那么消息将在队列中排队,由消费者自己控制消费速度
一条消息数据库持久化失败怎么办?
RabbitMq的路由机制是怎么实现的?
消息队列使用场景及其作用?
主要解决:应用耦合、异步消息、流量削锋等问题。实现高性能、高可用、可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件
如何保证RabbitMQ的消息可靠性传输?
生产者把消息发送到RabbitMQ Server的过程中丢失。
RabbitMQ提供了一个Confirm的消息确认机制,生产者发送消息后如果消息处理成功,Server端会返回一个ack的消息,那么客户端可以根据消息的处理结果,来决定是否要对消息进行重新发送。
避免不重复消费,最保险的机制就是消费者实现幂等性,保证就算重复消费,也不会有
RabbitMQ Server收到消息后在持久化之前宕机导致数据丢失。
可以开启持久化机制,创建Queue的时候设置为持久化,发送消息的时候,把消息投递模式设置为持久化投递。
消费端收到消息还没有来得及处理宕机,导致RabbitMQ Server认为这个消息已经签收。
可以把消息的自动确认机制修改成手动确认,消费端只有手动调用消息确认方法,才表示这个消息已经被签收。
RabbitMQ如何实现高可用
RabbitMQ提供2种集群模式,
- 第一普通集群模式,各个节点只同步元数据,不同步队列里面的消息,其中元数据包含队列的名称,交换机名称和属性,交换机与队列的绑定关系,当我们发送消息和消费消息的时候,不管消息发送到那个节点,都会通过元数据定位到队列所在的节点。去存储和拉取数据。好处就是分担了流量,提升了消息的吞吐能力。
- 第二个是镜像集群模式,队列中的每一个数据会在rabbitmq集群的每一个节点都存储一份。在镜像集群中,通过keepalived+haproxy来实现rabbitmq集群的负载均衡。
多线程异步和MQ的区别
多线程异步和MQ都支持程序的异步操作,
- 处理任务的维度不同:多线程异步:是进程内的概念,在一个进程中可以有多个线程并行处理任务。MQ异步:分布式消息队列,把消息发送发到不同应用节点的不同进程来处理任务。
- 消息的可靠性不同:多线程的数据是基于共享内存来交互的,MQ是消息队列的持久化机制来保证消息的可靠性。
- 分布式能力。MQ具备分布式能力。多线程只能在一个进程中处理任务
12. 算法
什么是时间轮?
定义一个固定长度的环装数组,然后数组的每一个元素代表一个时间刻度,假设为疫苗,那么如果是长度为8的一个环装数组,那么一圈代表8秒钟时间,有一个指针,按照顺时针无限循环这个数组,每隔最小的时间单位前进一个数组索引,这个指针转一圈代表8秒,当我们在时间轮里面添加一个定时任务的时候,我们会根据定时任务的执行时间,计算它所在的一个存储数组的一个下标。有可能在某个时间刻度上存在多个定时任务,那么我们会采用双向链表的方式来进行存储。当指针指向某个数组的时候,就会把存储的任务取出来。遍历这个链表,逐个运行里面的任务。
- 减少定时任务添加和11.Mysql
- 删除的时间复杂度,提升性能
- 可保证每次执行定时任务都是O(1)复杂度,在定时器任务密集的情况下,性能优势非常明显
缺点:对于执行时间非常严格的任务,时间轮并不是非常的适合,时间轮的最小精度取决于最小的时间单元,假如是1秒的任务,小于1秒钟的任务就无法被时间轮去管理
什么是令牌桶限流算法?
限流是在高并发情况下,保护系统稳定性的一种策略。限制无处不在,比如连接池和线程池都设置了最大并发数量,避免资源过度使用。或者在nginx反向代理服务器设置limit_conn去限制瞬时并发连接数。在方法层面上使用sentinel,或者ratelimiter这样子的机制,去限制接口并发请求数量。
- 针对什么资源进行限流,比如说接口或者连接等等。
- 第二个阈值,流量峰值达到多少以后,去限制后续流量访问。
- 触发限流后的一个行为。
限流算法是整个限流的实现核心。不同算法对流量的精确控制粒度不同,以及是否能支持突发流量。
常见的限流算法,滑动窗口,令牌桶,漏桶。
系统以恒定的速率向令牌图桶里面去添加令牌。然后每个请求都需要从令牌桶里面去获取令牌才能访问。如果获取不到就回触发限流,如果获取不到说明流量大于令牌的生成速率,也就是并发数量超过整个系统能够承载的阈值。就会触发限流的操作。在流量较低的情况下,令牌桶可以缓存一定数量的令牌,令牌桶可以去处理瞬时的突发流量
什么是滑动窗口?
滑动窗口是一种比较常见的数据统计算法,简单来说呢?就是在一个大的数组里面,去定义一个固定长度的滑动窗口,然后这个窗口在数组上进行滑动。滑动窗口一般用来解决数组的统计问题。
也就是数组,字符串的子元素问题。或者把嵌套的for循环问题,转化为单个for循环问题。hystrix有用到熔断触发的一个数据统计,在sentinel限流框架里面,也去实现了限流的水统计,不过都做了一点小的调整。
他们是通过时间线来去驱动窗口往前滑动的,hystrix定义了一个长度为10的数组,一个数组的长度,表示1秒的时间跨度,每个区间记录当前时间内的所有请求的成功数和失败数量,hystrix只需要统计对应的10个窗口的总的成功数和失败数,然后根据配置来决定是否要去触发熔断。
雪花算法的实现
雪花算法是生成全局唯一id算法,主要出现在分库分表场景中作为业务主键。
它是有一个64个bit组成的long 类型的数字,它分为4个部分,第一个部分是符号位,一般不是负数,所有一般是0,第二个部分是41个bit位表示一个时间戳,这个时间戳是系统时间的毫秒数,第三个bit位来记录工作机器的id。用12个bit位表示一个递增序列。
实现同毫秒内产生不同id的能力,
13. 场景题
在2g大小的文件中,找出高频top100的单词
2g大小的文件,意味着文件很大并且无法一次性load到内存里面,
- 首先把2g的文件进行分割成大小为512kb的小文件,总共得到2048个小文件,避免一次性读入整个文件造成内存不足。
- 定义一个长度为2048的hash表数组,用来统计每个小文件中单词出现的频率
- 使用多线程并行遍历2048个小文件,针对每个单词进行hash取模运算分别存储到长度为2048的hash表数组中。
- 接着在遍历着2048个hash表,把频率前100的单词存入小顶堆中
参考资料