Redis教程

Redis 入门
安装Redis
进入官网找到下载地址 https://redis.io/download
右键Download按钮,选择复制链接。 进入到Xshell控制台(默认当前是root根目录),输入wget 将上面复制的下载链接粘贴上,如下命令:
bashwget https://github.com/redis/redis/archive/7.2.0.tar.gz解压并安装Redis
下载完成后需要将压缩文件解压,输入以下命令解压到当前目录
bashtar -zvxf 7.2.0.tar.gz一般都会将redis目录放置到 /usr/local/redis目录,所以这里输入下面命令将目前在/root目录下的redis-5.0.7文件夹更改目录,同时更改文件夹名称为redis。
mv /root/redis-7.2.0 /usr/local/rediscd 到/usr/local目录下输入ls命令可以查询到当前目录已经多了一个redis子目录,同时/root目录下已经没有redis-5.0.7文件夹
bashcd /usr/local/redis编译
cd到/usr/local/redis目录,输入命令make执行编译命令,接下来控制台会输出各种编译过程中输出的内容。
make最终运行结果如下:
安装
make PREFIX=/usr/local/redis install这里多了一个关键字
PREFIX=这个关键字的作用是编译的时候用于指定程序存放的路径。比如我们现在就是指定了redis必须存放在/usr/local/redis目录。假设不添加该关键字Linux会将可执行文件存放在/usr/local/bin目录,库文件会存放在/usr/local/lib目录。配置文件会存放在/usr/local/etc目录。其他的资源文件会存放在usr/local/share目录。这里指定号目录也方便后续的卸载,后续直接rm -rf /usr/local/redis 即可删除redis。启动Redis-后台启动
根据上面的操作已经将redis安装完成了。在目录/usr/local/redis 输入下面命令启动redis
./bin/redis-server & ./redis.conf- 显示启动,退出窗口直接关闭
上面的启动方式是采取后台进程方式,下面是采取显示启动方式(如在配置文件设置了daemonize属性为yes则跟后台进程方式启动其实一样)。
./bin/redis-server ./redis.conf两种方式区别无非是有无带符号&的区别。 redis-server 后面是配置文件,目的是根据该配置文件的配置启动redis服务。redis.conf配置文件允许自定义多个配置文件,通过启动时指定读取哪个即可。
查看redis的进程是否开启
ps -ef|grep redis本地连接
redis -cli -h ip地址 -p 端口比如
redis -cli -h localhost -p 6379远程链接
将Redis.conf配置修改成一下内容
将bind 127.0.0.1 改为 bind 0.0.0.0
指定 Redis 只接收来自于该 IP 地址的请求,如果不进行设置,那么将处理所有请求,在 生产环境中最好设置该项
将 protected-mode yes 改为 protected-mode no
这一处就是开启保护模式,默认是开启状态,只允许本地客户端连接, 可以设置密码或添加bind来连接.这一处和requirepass这一项有关联
daemonize yes
默认情况下 redis 不是作为守护进程运行的,如果你想让它在后台运行,你就把它改成 yes。当redis作为守护进程运行的时候,它会写一个 pid 到 redis.pid 文件里面(pid名称见下面这条)
Docker安装
官网安装
https://docs.docker.com/engine/install/ubuntu/阿里云安装docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyunredis拉取
docker run -d -p 6379:6379 -v $PWD/conf/redis.conf:/usr/local/etc/redis/redis.conf -v $PWD/data:/data --name docker-redis docker.io/redis redis-server /usr/local/etc/redis/redis.conf --appendonly yes- -d:表示后台运行,不加-d执行上面的命令你就会看到redis启动的日志信息了
- -p:表示端口映射,冒号左面的是我们的宿主机的端口,也就是我们虚拟机的端口,而右侧则表示的是mysql容器内的端口
- --name:是我们给redis容器取的名字
- -v:表示挂载路径,$PWD表示当前目录下,冒号左面的表示我们宿主机的挂载目录,也就是我们虚拟机所在的文件路径,冒号右边则表是的是redis容器在容器内部的路径,上面的命令我分别挂载了redis.conf(redis的配置文件),如需使用配置文件的方式启动redis,这里则需要加上,还有redis存放数据所在的目录
- --appendonly yes:表示redis开启持久化策略
修改配置为
bind 0.0.0.0
protected-mode no
daemonize no阿里云加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://ip92h4jn.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart dockerRedis可视化工具
Redis Desktop Manager:可在Windows,Mac和Linux上运行,提供实时浏览器,键值查看器,服务器管理和导入/导出工具。
RedisInsight:RedisLabs的官方GUI,提供实时监视,查询可视化,慢查询日志和配置查看器。
Redis Commander:使用Node.js构建的开源GUI,提供简单易用的界面和基本的Redis操作。
Redis-cli:Redis官方命令行工具,可用于执行REDIS命令,并在终端中提供直观的Redis操作体验。
ReJSON:用于操作和处理JSON数据的Redis客户端,提供专业的JSON操作和灵活的数据存储。
Redsmin:可在云端使用的高级Redis管理工具,提供实时监视,分析和警报功能,以及实时追踪和日志分析。
Releases · qishibo/AnotherRedisDesktopManager (github.com)
Redis 数据类型
由于Redis中的不同数据类型会包含相同的元数据,所以值对象并不是直接存储,而是被包装成 redisObject 对象。Redis中的所有键和值都是redisObject变量。
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj其包含的属性如下:
- type:对象类型,如SDS、Set,占4bit,0.5字节
- encoding:编码格式,即存储数据使用的数据结构。同一个类型的数据,Redis会根据数据量、占用内存等情况使用不同的编码,占4bit,0.5字节
- lru:记录对象最后一次被访问的时间,或LFU计数,3字节
- refcount:引用计数,为了节省内存,redis会在多出引用同一个redisObject,等于0时表示可以被垃圾回收,占4字节
- ptr:指向底层实际的数据存储结构,比如SDS,真正的数据存储在该数据结构中。占8字节
type、encoding、lru使用了C语言中的位段定义,这3个属性使用同一个unsigned int的不同bit位。这样可以最大限度地节省内存。
type
| 对象 | type | type命令输出 |
|---|---|---|
| 字符串对象 | REDIS_STRING | string |
| 列表对象 | REDIS_LIST | list |
| 哈希对象 | REDIS_HASH | hash |
| 集合对象 | REDIS_SET | set |
| 有序集合对象 | REDIS_SET | zset |
set str1 v1
type str1
encoding 属性和 prt 指针
对象的 prt 指针指向对象底层的数据结构,而数据结构由 encoding 属性来决定。
| 编码常量 | 编码所对应的底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS _ENCODING_EMBSTR | embstr编码的简单动态字符串 |
| REDIS_ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ ENCODING_LINKEDLIST | 双端链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳跃表和字典 |
而每种类型的对象都至少使用了两种不同的编码:

可以通过如下命令查看值对象的编码:
OBJECT ENCODING key
比如 string 类型:(可以是 embstr编码的简单字符串或者是 int 整数值实现)

1) String
简介:String是Redis最基础的数据结构类型,它是二进制安全的,可以存储图片或者序列化的对象,值最大存储为512M
简单使用举例:
set key value、get key等.
应用场景:共享session、分布式锁,计数器、限流。
内部编码有3种,
int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
C语言的字符串是char[]实现的,而Redis使用SDS(simple dynamic string) 封装,sds源码如下:
struct sdshdr{
unsigned int len; // 标记buf的长度
unsigned int free; //标记buf中未使用的元素个数
char buf[]; // 存放元素的坑
}SDS 结构图如下:

Redis为什么选择SDS结构,而C语言原生的char[]不香吗?
举例其中一点,SDS中,O(1)时间复杂度,就可以获取字符串长度;而C 字符串,需要遍历整个字符串,时间复杂度为O(n)
字符串对象的编码可以是int,raw或者embstr。
1、int 编码:保存的是可以用 long 类型表示的整数值。
2、raw 编码:保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
3、embstr 编码:保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
set k1 1
set k2 hello
set k3 ffffdddddddddddddddwwwwwwwwwwwwwwwwwwwwdfssss
object encoding k1
object encoding k2
strlen k3
object encoding k3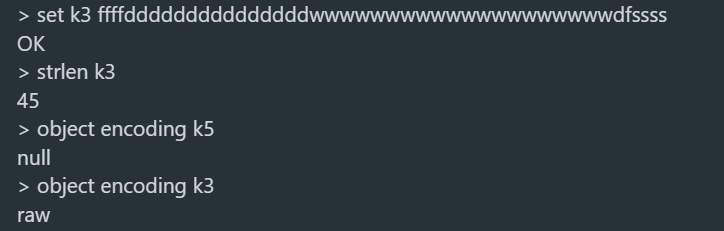
2) Hash(哈希)
- 简介:在Redis中,哈希类型是指v(值)本身又是一个键值对(k-v)结构
- 简单使用举例:
hset key field value、hget key field- 内部编码:
ziplist(压缩列表)、hashtable(哈希表)- 应用场景:缓存用户信息等。
- 注意点:如果开发使用hgetall,哈希元素比较多的话,可能导致Redis阻塞,可以使用hscan。而如果只是获取部分field,建议使用hmget。
字符串和哈希类型对比如下图:

编码结构
哈希对象的编码可以是 ziplist 或者 hashtable。
当使用ziplist,也就是压缩列表作为底层实现时,新增的键值对是保存到压缩列表的表尾。比如执行以下命令:
hset profile name "Tom"
hset profile age 25
hset profile career "Programmer"如果使用ziplist,profile 存储如下:

当使用 hashtable 编码时,上面命令存储如下:

hashtable 编码的哈希表对象底层使用字典数据结构,哈希对象中的每个键值对都使用一个字典键值对。
在前面介绍压缩列表时,我们介绍过压缩列表是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,相对于字典数据结构,压缩列表用于元素个数少、元素长度小的场景。其优势在于集中存储,节省空间。
②、编码转换
和上面列表对象使用 ziplist 编码一样,当同时满足下面两个条件时,使用ziplist(压缩列表)编码:
1、列表保存元素个数小于512个
2、每个元素长度小于64字节
不能满足这两个条件的时候使用 hashtable 编码。第一个条件可以通过配置文件中的 set-max-intset-entries 进行修改。
3) List(列表)
- 简介:列表(list)类型是用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素。
- 简单实用举例:
lpush key value [value ...]、lrange key start end - 内部编码:
ziplist(压缩列表)、linkedlist(链表) - 应用场景:消息队列,文章列表,
一图看懂list类型的插入与弹出:

编码转换
当同时满足下面两个条件时,使用ziplist(压缩列表)编码:
1、列表保存元素个数小于512个
2、每个元素长度小于64字节
不能满足这两个条件的时候使用 linkedlist 编码。
上面两个条件可以在redis.conf 配置文件中的 list-max-ziplist-value选项和 list-max-ziplist-entries 选项进行配置。
ziplist 编码表示如下:

linkedlist表示如下:

应用场景
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
4) Set(集合)

- 简介:集合(set)类型也是用来保存多个的字符串元素,但是不允许重复元素
- 简单使用举例:
sadd key element [element ...]、smembers key - 内部编码:
intset(整数集合)、hashtable(哈希表) - 注意点:smembers和lrange、hgetall都属于比较重的命令,如果元素过多存在阻塞Redis的可能性,可以使用sscan来完成。
- 应用场景:用户标签,生成随机数抽奖、社交需求。
编码转换
集合对象的编码可以是 intset 或者 hashtable。
intset 编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。
hashtable 编码的集合对象使用 字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值则全部设置为 null。这里可以类比Java集合中HashSet 集合的实现,HashSet 集合是由 HashMap 来实现的,集合中的元素就是 HashMap 的key,而 HashMap 的值都设为 null。
SADD numbers 1 3 5

SADD Dfruits "apple" "banana" "cherry"

②、编码转换
当集合同时满足以下两个条件时,使用 intset 编码:
1、集合对象中所有元素都是整数
2、集合对象所有元素数量不超过512
不能满足这两个条件的就使用 hashtable 编码。第二个条件可以通过配置文件的 set-max-intset-entries 进行配置。
5) Zset(有序集合)
- 简介:已排序的字符串集合,同时元素不能重复
- 简单格式举例:
zadd key score member [score member ...],zrank key member - 底层内部编码:
ziplist(压缩列表)、skiplist(跳跃表) - 应用场景:排行榜,社交需求(如用户点赞)。
编码转换
有序集合的编码可以是 ziplist 或者 skiplist。
ziplist 编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
ZADD price 8.5 apple 5.0 banana 6.0 cherry


skiplist 编码的有序集合对象使用 zet 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表:
typedef struct zset{
//跳跃表
zskiplist *zsl;
//字典
dict *dice;
} zset;字典的键保存元素的值,字典的值则保存元素的分值;跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。
这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。
说明:其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。
②、编码转换
当有序集合对象同时满足以下两个条件时,对象使用 ziplist 编码:
1、保存的元素数量小于128;
2、保存的所有元素长度都小于64字节。
不能满足上面两个条件的使用 skiplist 编码。以上两个条件也可以通过Redis配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改。
5) Geo
Redis3.2推出的,地理位置定位,用于存储地理位置信息,并对存储的信息进行操作。
6) HyperLogLog
redis HyperLogLog,看这篇就够了_柏油的博客-CSDN博客
用来做基数统计算法的数据结构,如统计网站的UV。
7) Bitmaps
用一个比特位来映射某个元素的状态,在Redis中,它的底层是基于字符串类型实现的,可以把bitmaps成作一个以比特位为单位的数组
Redis持久化
1) RDB
RDB是redis默认的持久化策略,当redis中写操作达到指定的次数同时距离上一次持久化达到指定的时间就会将redis内存中数据生成数据快照保存到指定的rdb文件中。
RDB默认触发持久化条件
| 900s 1次: | 当操作次数达到1次,900s就会进行持久化 |
|---|---|
| 300s 10次: | 当操作次数达到10次,300s就会进行持久化 |
| 60s 1000次: | 当操作次数达到10000次,60s就会进行持久化 |
操作次数越多,触发持久化的时间间隔就越短(防止数据丢失) ,我们可以通过修改redis.conf文件,来设置RDB策略的触发条件。
## rdb持久化策略开关
rdbcompression yes
## 配置rdb持久化策略
save 900 1
save 300 10
save 60 10000RDB持久化优点:
- 在数据量较小的情况下,执行速度比较快
- 由于RDB是以数据快照形式保存的,我们可以通过检索拷贝rdb文件轻松实现redis数据移植
RDB持久化缺点:
- 如果redis出现故障,存在数据丢失的风险,丢失上一次持久化之后的操作数据(因为每次持久化,都会有操作次数以及时间间隔)
- RDB采用的数据快照的形式进行的持久化,不适合实时性持久化 如果数据量庞大,在RDB持久化过程中生成数据快照子进程执行时间过长,会导致redis卡顿,因此Save的时间周期设置不宜过短(默认配置即可)
2) AOF
AOF(Append Only File),当达到设定的触发条件时,将redis执行的写操作指令存储到aof文件中,redis默认是未开启aof持久化的。
AOF默认持久化配置
| appendfsync always | 只要进行成功写操作,aof就执行 |
|---|---|
| appendfsync everysec | 每秒进行一次aof(默认) |
| appendfsync no | 让redis执行决定aof |
redis默认是AOF未开启的;可以通过将redis配置文件中‘appendonly no’修改为‘appendonly yes’进行开启 ;AOF也可以设置aof路径,默认是‘appendfilename "appendonly.aof"’
- 可以通过拷贝aof文件jinxingredis数据移植
- aof存储的是指令,而且会对指令进行整理,而RDB直接生成的数据快照,在数据量不大的时候会比较快
- aof是对文件进行增量更新,更适合实时性持久化
- redis官方建议是同时开启两种持久化策略,如果同时存在aof文件以及rdb文件,当我们需要进行数据移植的时候,优先选择aof(数据完整性会相对高一点)
AOF的优缺点:
优点:AOF相对RDB更加安全,一般不会有数据的丢失或者很少,官方推荐同时开启AOF和RDB。
缺点:AOF持久化的速度,相对于RDB较慢,存储的是一个文本文件,到了后期文件会比较大,传输困难。
Redis事务
Redis 管道
Redis 主从复制
Redis 复制实现中,把数据库分为 主数据库(master)和 从数据库(slave)。master 可以进行读写操作,slave 一般是只读的。当 master 数据变化的时候自动将数据同步给 slave。
主从复制的配置 master 节点不需要进行配置,slave 需要在 redis.conf中配置:
slaveof 主数据库ip 63791如果 master 设置了密码,需要添加配置
masterauth 密码主从切换的操作命令info replication:查看主从节点的相关信息。 slaveof:切换主节点。 slaveof no one:切换当前数据库为 master。
全量同步
Redis 全量复制一遍发生在 slave 初始化阶段,这时 slave 需要将 master 上的所有数据都复制一份。具体步骤如下:
- slave 连接 master,发送 SYNC 命令;
- master 接收到 SYNC 命名后,开始执行 BGSAVE命令生成 RDB快照文件并使用缓冲区记录此后执行的所有写命令;
- master BGSAVE执行完后,向所有 slave 发送快照文件,并在发送期间继续记录被执行的写命令;
- slave 收到快照文件后丢弃所有旧数据,载入收到的快照;
- master 快照发送完毕后开始向 slave 发送缓冲区中的写命令;
- slave 完成对快照的载入,开始接收命令请求,并执行来自 master 缓冲区的写命令;

增量同步
Redis 增量复制是指 slave 初始化后开始正常工作时 master 发生的写操作同步到 slave 的过程。
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset.如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
- 从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就获取从节点的offset值
- 主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步

Redis 分布式锁
概念
分布式锁的刚需
- 独占性:OnlyOne,任何时刻只能有且仅有一个线程持有
- 高可用:若redis集群环境下,不能因为某个节点挂 而出现获取锁和释放锁失败的情况
- 防死锁: 杜绝死锁,必须有超市控制机制或者撤销操作,有个兜底终止跳出方案
- 不乱抢:防止张冠李戴,不能私下unlock别人的锁,只能自己加锁自己释放。
- 重入性:同一个节点的同一个线程如果获得锁之后,它也能再次获得这个锁。
使用方法SETNX
SETNX:向Redis中添加一个key,只用当key不存在的时候才添加并返回1,存在则不添加返回0。并且这个命令是原子性的。 使用SETNX作为分布式锁时,添加成功表示获取到锁,添加失败表示未获取到锁。至于添加的value值无所谓可以是任意值(根据业务需求),只要保证多个线程使用的是同一个key,所以多个线程添加时只会有一个线程添加成功,就只会有一个线程能够获取到锁。而释放锁锁只需要将锁删除即可。
总结:
- 获取锁:通过setnx添加
- 释放锁:通过del将锁删除

设置过期时间防止死锁
假设线程1通过SETNX获取到锁并且正常执行然后释放锁那么一切ok,其它线程也能获取到锁。但是线程1现在"耍脾气"了,线程1抱怨说"工作太久有点累需要休息一下,你们想要获取锁等着吧,等我把活干完你们再来获取锁"。此时其它线程就无法向下继续执行,因为锁在线程1手中。这种长期不释放锁情况就有可能造成死锁。
为了防止像线程1这种"耍脾气"的现象发生,我们可以设置key的过期时间来解决。设置过期时间过后其它线程可不会惯着线程1,其它线程表示你要休息可以,休息了指定时间把锁让出来然后拍拍屁股走人,没人惯着你。Redis命令:
set key value [EX seconds] [PX milliseconds] [NX|XX]- EX: key在多少秒之后过期
- PX: key在多少毫秒之后过期
- NX:当key不存在的时候,才创建key,效果等同于setnx·
- XX:当key存在的时候,覆盖key
java代码
//通过java代码实现SETNX同时设置过期时间
//key--键 value--值 time--过期时间 TimeUnit--时间单位枚举
stringRedisTemplate.opsForValue().setIfAbsent(key, value , time, TimeUnit);整合SpringBoot
添加jar包
<!-- 引入整合Redis缓存的依赖启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- redisson分布式锁依赖 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.11.6</version>
</dependency>如果报错可以试试这个
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.18.1</version>
</dependency>添加配置代码
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import org.springframework.stereotype.Component;
import java.time.Duration;
@Component
@Configuration // 定义一个配置类
public class RedisConfig {
@Value("${spring.redis.host}")
private String address;
@Value("${spring.redis.port}")
private String port;
@Bean
public RedissonClient singletonModeRedisson() {
Config config = new Config();
// 使⽤"redis://"来启⽤SSL连接
config.useSingleServer().setAddress("redis://"+address+":"+port);
return Redisson.create(config);
}
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
// 使用JSON格式序列化对象,对缓存数据key和value进行转换
Jackson2JsonRedisSerializer jacksonSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
// 解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jacksonSerializer.setObjectMapper(om);
// 设置RedisTemplate模板API的序列化方式为JSON
template.setDefaultSerializer(jacksonSerializer);
return template;
}
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory redisConnectionFactory){
// 序列化value
Jackson2JsonRedisSerializer jacksonSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
// 序列化key
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jacksonSerializer.setObjectMapper(om);
RedisCacheConfiguration configuration = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofDays(1)) //配置缓存数据的默认存活时间1天
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(stringRedisSerializer)
) // 指定key进行序列化
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(jacksonSerializer)
)
.disableCachingNullValues(); // null不参与序列化操作
RedisCacheManager cacheManager = RedisCacheManager.builder(redisConnectionFactory).cacheDefaults(configuration).build();
return cacheManager;
}
}Controller层
package com.jiema.human.controller;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.bind.annotation.*;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
@RestController
@RequestMapping("redis")
public class RedisController {
@Autowired
private RedissonClient redisson;
@Autowired
private StringRedisTemplate stringRedisTemplate;
//高并发下会出现超买,没有加锁
@GetMapping("/reduct01")
public String reduct01() {
Integer stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock < 0) {
System.out.println("扣减失败,库存不足");
} else {
Integer realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}
return "end";
}
//高并发下单机模式不会出现超买,但是在分布式环境下,仍然会出现超买的现象
@GetMapping("/reduct02")
public String reduct02() {
// 添加了sychronized
synchronized (this) {
Integer stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock < 0) {
System.out.println("扣减失败,库存不足");
} else {
Integer realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}
}
return "end";
}
@GetMapping("/set")
public String set() {
stringRedisTemplate.opsForValue().set("stock", String.valueOf(100));
return "end";
}
//通过setnx key value命令,对商品库存进行加锁
@GetMapping("/reduct03")
public String reduct03() {
//这里的key一般设置为和商品有关的key,以提高性能
String lockKey = "product_01";
//这里可以将value设置为线程id
String value = UUID.randomUUID().toString();
// stringRedisTemplate.opsForValue().setIfAbsent(lockKey,"setnx"); -> setnx key value
// stringRedisTemplate.expire(lockKey,10,TimeUnit.SECONDS);
//设置setnx和超时时间要原子操作
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, value, 10, TimeUnit.SECONDS);
if (!flag) {
//加锁失败
return "error code";
}
/**
* 因为在操作的过程中,可能会抛出异常,因此我们要用try将代码块包起来,然后在finally中,释放锁,否则会出现因为异常退出,但锁在redis中存在,从而
* 使其他线程在访问该商品时加锁失败,无法顺利扣减库存
*/
try {
Integer stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock < 0) {
System.out.println("扣减失败,库存不足");
} else {
Integer realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}
} finally {
//双重保证,将value设置为当前线程的id,保证锁不会被其他线程删掉
if (value.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
//删除锁
stringRedisTemplate.delete(lockKey);
}
}
return "end";
}
/**
* 在上面的reduct03代码中,我们通过setnx key value进行加锁,我们设置的超时时间是10秒,假设当前商品库存为100,现在线程A访问该方法,获取到
* 锁,然后在执行业务代码时,执行的时间超过了10秒,此时锁过期了,这时线程B访问该方法,获取到锁,获取商品库存为100,这样当A和B线程都执行完毕后,
* 商品的库存实际上,只减少了1,也就是变成99,从而导致超买,那么我们需要在锁过期前,进行续期,因此使用redisson
*
* @return
*/
@GetMapping("/reduct04")
public String reduct04() {
String lockKey = "product_01";
RLock redissonLock = redisson.getLock(lockKey);
try {
redissonLock.lock();
Integer stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if (stock < 0) {
System.out.println("扣减失败,库存不足");
} else {
Integer realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}
} finally {
redissonLock.unlock();
//删除锁
stringRedisTemplate.delete(lockKey);
}
return "end";
}
/**
* 考虑一种情况,我们使用redis集群,当设置key的时候,主节点甲会异步地将数据同步到其他从节点,假设现在线程A扣减商品product1库存,那么它在主节点A中设置可以,
* 但是假设主节点A在同步数据之前挂了,数据没同步到从节点,现在从节点乙推选为主节点,线程B访问主节点乙,然后也是访问商品product1,设置key值,然后假设A、B线
* 程同时结束,这个时候,会出现超买问题。根本原因是Redis主从同步是异步的,我们可以使用zookeeper来加分布式锁,zookeeper在主从同步时,主节点设置成功后,会
* 先同步给从节点,只有集群中有一半以上同步后,才返回true,而即使主节点挂了,在推选主节点的时候,选择的也会是数据最完善的那个,因此不会出现刚才的问题,但带来
* 的问题就是,zookeeper的性能比redis差
*/
// @RequestMapping("/deduct_stock")
// public String deductStock(){
//锁住的lock要以资源为名,提高效率
// String lockKey="product_001";
//
// //可以设置为线程id
// String clientId= UUID.randomUUID().toString();
//
// //jedis.setnx(key,value)
// Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, "zhuge");
// stringRedisTemplate.expire(lockKey,10, TimeUnit.SECONDS);
//
// //加锁和设置过时时间要原子操作,考虑问题,执行时间大于超时时间?
// Boolean result=stringRedisTemplate.opsForValue().setIfAbsent(lockKey,clientId,10,TimeUnit.SECONDS);
//
// if (!result){
// return "error_code";
// }
//
// try{
// int stock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock");
// if (stock>0){
// int realStock=stock-1;
// stringRedisTemplate.opsForValue().set("stock",realStock+"");
// System.out.println("扣减成功,剩余库存:"+realStock);
// }else{
// System.out.println("扣减失败,库存不足");
// }
// }finally {
// if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {
// //当前线程的id和取出来的id相同时,才解锁
// stringRedisTemplate.delete(lockKey);
// }
// }
// return "end";
//
// String lockKey="product_001";
//
// RLock redissonLock = redisson.getLock(lockKey);
//
// try{
// redissonLock.lock();
// int stock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
// if (stock>10){
// int realStock=stock-1;
// stringRedisTemplate.opsForValue().set("stock",realStock+"");
// System.out.println("扣减成功,剩余库存:"+realStock);
// }else{
// System.out.println("扣减失败,库存不足");
// }
// }finally {
// redissonLock.unlock();
// }
// return "end";
// }
}红锁
Redlock 算法是 Redis 的作者 Antirez 提出的一种分布式锁的算法,它可以在一定程度上解决单点故障和时钟漂移的问题。Redlock 算法的基本思想是,使用多个 Redis 实例来存储锁,客户端需要同时向多个实例请求加锁和解锁,只有当大多数实例同意时,才认为操作成功。
Redlock 算法的具体步骤如下:
- 加锁:客户端获取当前时间戳,然后依次向 N 个 Redis 实例发送 SETNX 命令,将 key 设置为 lock,value 设置为一个随机字符串,并设置一个过期时间。如果向某个实例发送命令失败,就立即重试,直到成功或超时。然后客户端计算从获取时间戳到完成加锁的总耗时,如果超过了过期时间的一半,就认为加锁失败;否则,如果成功加锁的实例数超过了 N/2,就认为加锁成功,并返回 value;否则,就认为加锁失败,并向所有实例发送 DEL 命令,释放锁。
- 解锁:客户端向所有实例发送 GET 命令,获取 key 的值,并与自己保存的随机字符串比较。如果相同,表示是自己加的锁,就可以向所有实例发送 DEL 命令,删除 key,释放锁;如果不同,表示是别人加的锁,就不做任何操作。
Redlock 算法的优点是,它可以容忍少数实例故障或网络分区,只要大多数实例正常工作,就可以保证锁的正确性。它也可以避免单点故障导致的死锁。它的缺点是,它需要多个 Redis 实例和多次网络通信,可能会增加复杂度和开销。它也不能完全消除时钟漂移的影响,只能尽量减小其概率和影响。
IO多路复用
1) 什么是IO多路复用
IO即为网络I/O,多路即为多个TCP连接,复用即为共用一个线程或者进程,模型最大的优势是系统开销小,不必创建也不必维护过多的线程或进程。
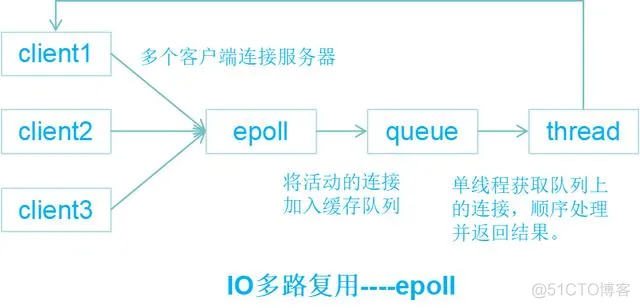
IO多路复用是经典的Reactor设计模式,有时也称为异步阻塞IO(异步指socket为non-blocking,堵塞指select堵塞),为常见的四种IO模型之一,
其他三种分别是:同步堵塞IO、同步非堵塞IO、异步(非堵塞)IO。
2) 五种IO模型
[1]blockingIO - 阻塞IO
[2]nonblockingIO - 非阻塞IO
[3]signaldrivenIO - 信号驱动IO
[4]asynchronousIO - 异步IO
[5]IOmultiplexing - IO多路复用
同步阻塞IO-BIO
- 服务器端启动一个 ServerSocket。
- 客户端启动 Socket 对服务器进行通信,默认情况下服务器端需要对每个客户建立一个线程与之通讯。
- 客户端发出请求后,先咨询服务器是否有线程响应,如果没有则会等待,或者被拒绝。
- 如果有响应,客户端线程会等待请求结束后,再继续执行。

服务端代码
package mythread;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class BIOServer {
public static void main(String[] args) throws IOException {
ExecutorService service = Executors.newCachedThreadPool();
ServerSocket serverSocket = new ServerSocket(6666);
System.out.println("服务器启动了");
while (true) {
System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
//监听,等待客户端连接
System.out.println("等待连接....");
//会阻塞在accept()
final Socket socket = serverSocket.accept();
System.out.println("连接到一个客户端");
//就创建一个线程,与之通讯(单独写一个方法)
service.execute(new Runnable() {
public void run() {//我们重写
//可以和客户端通讯
handler(socket);
}
});
}
}
//编写一个handler方法,和客户端通讯
public static void handler(Socket socket) {
BufferedReader socketReader = null;
BufferedWriter socketWrite = null;
try {
// 通过socket获取字节流,然后包装成字符缓冲流
socketReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
socketWrite = new BufferedWriter(new OutputStreamWriter(new BufferedOutputStream(socket.getOutputStream())));
String inMsg = null;
// 获取客户端传输到服务端的消息
while ((inMsg = socketReader.readLine()) != null) {
System.out.println("接收到客户端的消息:" + inMsg);
String outMsg = "喵喵喵";
// 向客户端响应消息
socketWrite.write(outMsg);
socketWrite.write("\n");
socketWrite.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 手动关闭资源
if (socketReader != null) {
try {
socketReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (socketWrite != null) {
try {
socketWrite.close();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
// try {
// System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
// byte[] bytes = new byte[1024];
// //通过socket获取输入流
// InputStream inputStream = socket.getInputStream();
// //循环的读取客户端发送的数据
// while (true) {
// System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
// System.out.println("read....");
// int read = inputStream.read(bytes);
// if (read != -1) {
// System.out.println(new String(bytes, 0, read));//输出客户端发送的数据
// } else {
// break;
// }
// }
// } catch (Exception e) {
// e.printStackTrace();
// } finally {
// System.out.println("关闭和client的连接");
// try {
// socket.close();
// } catch (Exception e) {
// e.printStackTrace();
// }
// }
}
}客户端代码
package mythread;
import java.io.*;
import java.net.Socket;
public class BIOClient {
public static void main(String[] args) throws IOException {
// 创建socket,并指定服务器的ip(host) 和 端口
Socket socket = new Socket("localhost", 6666);
// 获取socket所绑定的本地地址
System.out.println("启动客户端:" + socket.getLocalAddress());
// 通过socket获取字节流,并包装成字符缓冲流
BufferedReader socketReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
BufferedWriter socketWrite = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
// 通过控制台输入发送给服务端的消息,并把字节流包装成字符缓冲流
BufferedReader consoleReader = new BufferedReader(new InputStreamReader(System.in));
String promptMsg = "请输入消息(输入bye退出):";
String outMsg = null;
// 提示语
System.out.println(promptMsg);
// 获取控制台输入内容,每次一行
while ((outMsg = consoleReader.readLine()) != null) {
if (outMsg.equalsIgnoreCase("bye")) {
break;
}
// 向服务器发送一行消息,因为服务器每次读取一行
socketWrite.write(outMsg);
socketWrite.write("\n");
socketWrite.flush();
// 读取并显示来自服务器的消息
String inMsg = socketReader.readLine();
System.out.println("来自服务器的消息:" + inMsg);
System.out.println(); // 输出一个空白行
System.out.println(promptMsg);
}
// 关闭资源,socket关闭时,其对应的流也会关闭,为了防止内存泄漏,
// 可以手动关闭其他流对象,这里偷个懒
socket.close();
}
}客户端启动

服务端接受到信息

NIO
- NIO 有三大核心部分:Channel(通道)、Buffer(缓冲区)、Selector(选择器) 。
- NIO 是面向缓冲区,或者面向块编程的。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动,这就增加了处理过程中的灵活性,使用它可以提供非阻塞式的高伸缩性网络。
- Java NIO 的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
- 通俗理解:NIO 是可以做到用一个线程来处理多个操作的。假设有 10000 个请求过来,根据实际情况,可以分配 50 或者 100 个线程来处理。不像之前的阻塞 IO 那样,非得分配 10000 个。
信号驱动IO

当进程发起一个IO操作,会向内核注册一个信号处理函数,然后进程返回不阻塞;当内核数据就绪时会发送一个信号给进程,进程便在信号处理函数中调用IO读取数据。
特点:回调机制,实现、开发应用难度大;
异步IO

当进程发起一个IO操作,进程返回(不阻塞),但也不能返回果结;内核把整个IO处理完后,会通知进程结果。如果IO操作成功则进程直接获取到数据。
特点:
- 不阻塞,数据一步到位;Proactor模式;
- 需要操作系统的底层支持,LINUX 2.5 版本内核首现,2.6 版本产品的内核标准特性;
- 实现、开发应用难度大;
- 非常适合高性能高并发应用;
IO复用模型

大多数文件系统的默认IO操作都是缓存IO。在Linux的缓存IO机制中,操作系统会将IO的数据缓存在文件系统的页缓存(page cache)。也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓存区拷贝到应用程序的地址空间中。这种做法的缺点就是,需要在应用程序地址空间和内核进行多次拷贝,这些拷贝动作所带来的CPU以及内存开销是非常大的。
至于为什么不能直接让磁盘控制器把数据送到应用程序的地址空间中呢?最简单的一个原因就是应用程序不能直接操作底层硬件。
总的来说,IO分两阶段:
1)数据准备阶段
2)内核空间复制回用户进程缓冲区阶段。如下图:

IO多路复用的核心是可以同时处理多个连接请求,为此使用了两个系统调用,分别是:
select/poll/epoll--模型机制:可以监视多个描述符(fd),一旦某个描述符就绪(读/写/异常)就能通知程序进行相应的读写操作。读写操作都是自己负责的,也即是阻塞的,所以本质上都是同步(堵塞)IO。
Redis支持这三种机制,默认使用epoll机制。

我们来看一下epoll原理:

3) I/O 多路复用
前期知识
socket
套接字。对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。例子︰客户端将数据通过网线发送到服务端,客户端发送数据需要一个出口,服务端接收数据需要一个入口,这两个“口子”就是Socket。\
FD
文件描述符,非负整数。“一切皆文件”,linux中的一切资源都可以通过文件的方式访问和管理。而FD就类似文件的索引(符号),指向某个资源,内核(kernel)利用FD来访问和管理资源。
目前支持I/O多路复用的系统调用有select,pselect,poll,epoll。与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds,当用户process调用select的时候,select会将需要监控的readfds集合拷贝到内核空间(假设监控的仅仅是socket可读),然后遍历自己监控的skb(SocketBuffer),挨个调用skb的poll逻辑以便检查该socket是否有可读事件,遍历完所有的skb后,如果没有任何一个socket可读,那么select会调用schedule_timeout进入schedule循环,使得process进入睡眠。
如果在timeout时间内某个socket上有数据可读了,或者等待timeout了,则调用select的process会被唤醒,接下来select就是遍历监控的集合,挨个收集可读事件并返回给用户了,相应的伪码如下:
int select(
int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
// nfds:监控的文件描述符集里最大文件描述符加1
// readfds:监控有读数据到达文件描述符集合,传入传出参数
// writefds:监控写数据到达文件描述符集合,传入传出参数
// exceptfds:监控异常发生达文件描述符集合, 传入传出参数
// timeout:定时阻塞监控时间,3种情况
// 1.NULL,永远等下去
// 2.设置timeval,等待固定时间
// 3.设置timeval里时间均为0,检查描述字后立即返回,轮询
/*
* select服务端伪码
* 首先一个线程不断接受客户端连接,并把socket文件描述符放到一个list里。
*/
while(1) {
connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
fdlist.add(connfd);
}
/*
* select函数还是返回刚刚提交的list,应用程序依然list所有的fd,只不过操作系统会将准备就绪的文件描述符做上标识,
* 用户层将不会再有无意义的系统调用开销。
*/
struct timeval timeout;
int max = 0; // 用于记录最大的fd,在轮询中时刻更新即可
// 初始化比特位
FD_ZERO(&read_fd);
while (1) {
// 阻塞获取 每次需要把fd从用户态拷贝到内核态
nfds = select(max + 1, &read_fd, &write_fd, NULL, &timeout);
// 每次需要遍历所有fd,判断有无读写事件发生
for (int i = 0; i <= max && nfds; ++i) {
// 只读已就绪的文件描述符,不用过多遍历
if (i == listenfd) {
// 这里处理accept事件
FD_SET(i, &read_fd);//将客户端socket加入到集合中
}
if (FD_ISSET(i, &read_fd)) {
// 这里处理read事件
}
}
}下面的动图能更直观的让我们了解select:

- 首先用户线程发起select系统调用的时候会阻塞在select系统调用上,此时用户线程从用户态切换到内核态完成了一次上下文切换
- 用户线程将需要监听的socket对应的文件描述符fd数组通过select系统调用传递给内核。此时,用户线程将用户 空间的fd数组拷贝拷贝到内核空间。
- 这里的文件文件描述符数组其实是一个BitMap,BitMap下标为文件描述符fd,下标对应的值为:1表示该fd上拥有读写事件,0表示该fd上没有读写事件

通过上面的select逻辑过程分析,相信大家都意识到,select存在三个问题:
[1] 每次调用select,都需要把被监控的fds集合从用户态空间拷贝到内核态空间,高并发场景下这样的拷贝会使得消耗的资源是很大的。 [2] 能监听端口的数量有限,单个进程所能打开的最大连接数由FD_SETSIZE宏定义,监听上限就等于fds_bits位数组中所有元素的二进制位总数,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上为3264),当然我们可以对宏FD_SETSIZE进行修改,然后重新编译内核,但是性能可能会受到影响,一般该数和系统内存关系很大,具体数目可以
cat /proc/sys/fs/file-max察看。32位机默认1024个,64位默认2048。

[3] 被监控的fds集合中,只要有一个有数据可读,整个socket集合就会被遍历一次调用sk的poll函数收集可读事件:由于当初的需求是朴素,仅仅关心是否有数据可读这样一个事件,当事件通知来的时候,由于数据的到来是异步的,我们不知道事件来的时候,有多少个被监控的socket有数据可读了,于是,只能挨个遍历每个socket来收集可读事件了。
poll
poll的实现和select非常相似,只是描述fd集合的方式不同。
针对select遗留的三个问题中(问题(2)是fd限制问题,问题(1)和(3)则是性能问题),poll只是使用pollfd结构而不是select的fd_set结构,这就解决了select的问题(2)fds集合大小1024限制问题。但poll和select同样存在一个性能缺点就是包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
下面是poll的函数原型,poll改变了fds集合的描述方式,使用了pollfd结构而不是select的fd_set结构,使得poll支持的fds集合限制远大于select的1024。poll虽然解决了fds集合大小1024的限制问题,从实现来看。很明显它并没优化大量描述符数组被整体复制于用户态和内核态的地址空间之间,以及个别描述符就绪触发整体描述符集合的遍历的低效问题。poll随着监控的socket集合的增加性能线性下降,使得poll也并不适合用于大并发场景。
int poll(struct pollfd *ufds, unsigned int nfds, int timeout);
struct pollfd {
int fd; /*文件描述符*/
short events; /*监控的事件*/
short revents; /*监控事件中满足条件返回的事件*/
};
int poll(struct pollfd *fds, nfds_tnfds, int timeout);
poll服务端实现伪码:
struct pollfd fds[POLL_LEN];
unsigned int nfds=0;
fds[0].fd=server_sockfd;
fds[0].events=POLLIN|POLLPRI;
nfds++;
while {
res=poll(fds,nfds,-1);
if(fds[0].revents&(POLLIN|POLLPRI)) {
//执行accept并加入fds中,nfds++
if(--res<=0) continue
}
//循环之后的fds
if(fds[i].revents&(POLLIN|POLLERR )) {
//读操作或处理异常等
if(--res<=0) continue
}
}epoll
epoll函数模型主要是调用了三个函数:epoll_create() , epoll_ctl() , epoll_wait(); 底层流程:
①通过epoll_create() 函数创建一个文件,返回一个文件描述符(Linus系统一切对象皆为文件)fd
② 创建socket接口号4,绑定socket号与端口号,监听事件,标记为非阻塞。通过epoll_ctl() 函数将该socket号 以及 需要监听的事件(如listen事件)写入fd中。
③循环调用epoll_wait() 函数进行监听,返回已经就绪事件序列的长度(返回0则说明无状态,大于0则说明有n个事件已就绪)。例如如果有客户端进行连接,则,再调用accept()函数与4号socket进行连接,连接后返回一个新的socket号,且需要监听读事件,则再通过epoll_ctl()将新的socket号以及对应的事件(如read读事件)写入fd中,epoll_wait()进行监听。循环往复。
优点:不需要再遍历所有的socket号来获取每一个socket的状态,只需要管理活跃的连接。即监听在通过epoll_create()创建的文件中注册的socket号以及对应的事件。只有产生就绪事件,才会处理,所以操作都是有效的,为O(1). 补充:众所周知,设备(进程)是通过中断机制来请求CPU进行IO处理。使用epoll模型能加快CPU的处理效率。如网卡想通过IO来向系统传输一个数据,就通过中断获取CPU时间片,将该数据放置就绪事件序列中,等待CPU下一次进行epoll_wait()即可获取到对应数据,无需再通过往fd中注册socket号对应的事件等等。
在linux的网络编程中,很长的时间都在使用select来做事件触发。在linux新的内核中,有了一种替换它的机制,就是epoll。相比于select,epoll最大的好处在于它不会随着监听fd数目的增长而降低效率。如前面我们所说,在内核中的select实现中,它是采用轮询来处理的,轮询的fd数目越多,自然耗时越多。
并且,在linux/posix_types.h头文件有这样的声明: #define __FD_SETSIZE 1024 表示select最多同时监听1024个fd,当然,可以通过修改头文件再重编译内核来扩大这个数目,但这似乎并不治本。
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
epoll的接口非常简单,一共就三个函数:
epoll_create:创建一个epoll句柄epoll_ctl:向 epoll 对象中添加/修改/删除要管理的连接epoll_wait:等待其管理的连接上的 IO 事件
epoll_create 函数
int epoll_create(int size);- **功能:**该函数生成一个 epoll 专用的文件描述符。
- 参数size: 用来告诉内核这个监听的数目一共有多大,参数 size 并不是限制了 epoll 所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。自从 linux 2.6.8 之后,size 参数是被忽略的,也就是说可以填只有大于 0 的任意值。
- **返回值:**如果成功,返回poll 专用的文件描述符,否者失败,返回-1。
epoll_create的源码实现:
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
struct eventpoll *ep = NULL;
//创建一个 eventpoll 对象
error = ep_alloc(&ep);
}
//struct eventpoll 的定义
// file:fs/eventpoll.c
struct eventpoll {
//sys_epoll_wait用到的等待队列
wait_queue_head_t wq;
//接收就绪的描述符都会放到这里
struct list_head rdllist;
//每个epoll对象中都有一颗红黑树
struct rb_root rbr;
......
}
static int ep_alloc(struct eventpoll **pep)
{
struct eventpoll *ep;
//申请 epollevent 内存
ep = kzalloc(sizeof(*ep), GFP_KERNEL);
//初始化等待队列头
init_waitqueue_head(&ep->wq);
//初始化就绪列表
INIT_LIST_HEAD(&ep->rdllist);
//初始化红黑树指针
ep->rbr = RB_ROOT;
......
}其中eventpoll 这个结构体中的几个成员的含义如下:
- wq: 等待队列链表。软中断数据就绪的时候会通过 wq 来找到阻塞在 epoll 对象上的用户进程。
- rbr: 红黑树。为了支持对海量连接的高效查找、插入和删除,eventpoll 内部使用的就是红黑树。通过红黑树来管理用户主进程accept添加进来的所有 socket 连接。
- rdllist: 就绪的描述符链表。当有连接就绪的时候,内核会把就绪的连接放到 rdllist 链表里。这样应用进程只需要判断链表就能找出就绪进程,而不用去遍历红黑树的所有节点了。
epoll_ctl 函数
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);- **功能:**epoll 的事件注册函数,它不同于 select() 是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。
- 参数epfd: epoll 专用的文件描述符,epoll_create()的返回值
- 参数op: 表示动作,用三个宏来表示:
- EPOLL_CTL_ADD:注册新的 fd 到 epfd 中;
- EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
- EPOLL_CTL_DEL:从 epfd 中删除一个 fd;
- 参数fd: 需要监听的文件描述符
- 参数event: 告诉内核要监听什么事件,struct epoll_event 结构如:
- events****可以是以下几个宏的集合:
- EPOLLIN :表示对应的文件描述符可以读(包括对端 SOCKET 正常关闭);
- EPOLLOUT:表示对应的文件描述符可以写;
- EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
- EPOLLERR:表示对应的文件描述符发生错误;
- EPOLLHUP:表示对应的文件描述符被挂断;
- EPOLLET :将 EPOLL 设为边缘触发(Edge Trigger)模式,这是相对于水平触发(Level Trigger)来说的。
- EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个 socket 的话,需要再次把这个 socket 加入到 EPOLL 队列里
- **返回值:**0表示成功,-1表示失败。
epoll_wait函数
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);- **功能:**等待事件的产生,收集在 epoll 监控的事件中已经发送的事件,类似于 select() 调用。
- 参数epfd: epoll 专用的文件描述符,epoll_create()的返回值
- 参数events: 分配好的 epoll_event 结构体数组,epoll 将会把发生的事件赋值到events 数组中(events 不可以是空指针,内核只负责把数据复制到这个 events 数组中,不会去帮助我们在用户态中分配内存)。
- 参数maxevents: maxevents 告之内核这个 events 有多少个 。
- 参数timeout: 超时时间,单位为毫秒,为 -1 时,函数为阻塞。
- 返回值:
- 如果成功,表示返回需要处理的事件数目
- 如果返回0,表示已超时
- 如果返回-1,表示失败
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <fcntl.h>
#include <stdlib.h>
#include <cassert>
#include <sys/epoll.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include<iostream>
const int MAX_EVENT_NUMBER = 10000; //最大事件数
// 设置句柄非阻塞
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
int main(){
// 创建套接字
int nRet=0;
int m_listenfd = socket(PF_INET, SOCK_STREAM, 0);
if(m_listenfd<0)
{
printf("fail to socket!");
return -1;
}
//
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_addr.s_addr = htonl(INADDR_ANY);
address.sin_port = htons(6666);
int flag = 1;
// 设置ip可重用
setsockopt(m_listenfd, SOL_SOCKET, SO_REUSEADDR, &flag, sizeof(flag));
// 绑定端口号
int ret = bind(m_listenfd, (struct sockaddr *)&address, sizeof(address));
if(ret<0)
{
printf("fail to bind!,errno :%d",errno);
return ret;
}
// 监听连接fd
ret = listen(m_listenfd, 200);
if(ret<0)
{
printf("fail to listen!,errno :%d",errno);
return ret;
}
// 初始化红黑树和事件链表结构rdlist结构
epoll_event events[MAX_EVENT_NUMBER];
// 创建epoll实例
int m_epollfd = epoll_create(5);
if(m_epollfd==-1)
{
printf("fail to epoll create!");
return m_epollfd;
}
// 创建节点结构体将监听连接句柄
epoll_event event;
event.data.fd = m_listenfd;
//设置该句柄为边缘触发(数据没处理完后续不会再触发事件,水平触发是不管数据有没有触发都返回事件),
event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
// 添加监听连接句柄作为初始节点进入红黑树结构中,该节点后续处理连接的句柄
epoll_ctl(m_epollfd, EPOLL_CTL_ADD, m_listenfd, &event);
//进入服务器循环
while(1)
{
int number = epoll_wait(m_epollfd, events, MAX_EVENT_NUMBER, -1);
if (number < 0 && errno != EINTR)
{
printf( "epoll failure");
break;
}
for (int i = 0; i < number; i++)
{
int sockfd = events[i].data.fd;
// 属于处理新到的客户连接
if (sockfd == m_listenfd)
{
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int connfd = accept(m_listenfd, (struct sockaddr *)&client_address, &client_addrlength);
if (connfd < 0)
{
printf("errno is:%d accept error", errno);
return false;
}
epoll_event event;
event.data.fd = connfd;
//设置该句柄为边缘触发(数据没处理完后续不会再触发事件,水平触发是不管数据有没有触发都返回事件),
event.events = EPOLLIN | EPOLLRDHUP;
// 添加监听连接句柄作为初始节点进入红黑树结构中,该节点后续处理连接的句柄
epoll_ctl(m_epollfd, EPOLL_CTL_ADD, connfd, &event);
setnonblocking(connfd);
}
else if (events[i].events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR))
{
//服务器端关闭连接,
epoll_ctl(m_epollfd, EPOLL_CTL_DEL, sockfd, 0);
close(sockfd);
}
//处理客户连接上接收到的数据
else if (events[i].events & EPOLLIN)
{
char buf[1024]={0};
read(sockfd,buf,1024);
printf("from client :%s");
// 将事件设置为写事件返回数据给客户端
events[i].data.fd = sockfd;
events[i].events = EPOLLOUT | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
epoll_ctl(m_epollfd, EPOLL_CTL_MOD, sockfd, &events[i]);
}
else if (events[i].events & EPOLLOUT)
{
std::string response = "server response \n";
write(sockfd,response.c_str(),response.length());
// 将事件设置为读事件,继续监听客户端
events[i].data.fd = sockfd;
events[i].events = EPOLLIN | EPOLLRDHUP;
epoll_ctl(m_epollfd, EPOLL_CTL_MOD, sockfd, &events[i]);
}
//else if 可以加管道,unix套接字等等数据
}
}
}如下图,可以帮助我们理解的更加丝滑(/手动狗头):

服务器端在调用accept系统调用之后,开始阻塞,当有客户端连接上来并完成TCP三次握手之后,内核就会创建一个对应的socket作为socket和客户端通信的内核接口。在linux下一切皆文件,所以当内核创建一个socket以后,当前进程就会将这个socket加入文件打开列表进行管理。

总结
select,poll,epoll都是IO多路复用机制,即可以监视多个描述符,一旦某个描述符就绪(读或写就绪),能够通知程序进行相应读写操作。 但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
- select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
- select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
| select | poll | epoll | |
|---|---|---|---|
| 性能 | 随着连接数的增加,性能急剧下降,处理成千上万的并发连接数时,性能很差 | 随着连接数的增加,性能急剧下降,处理成千上万的并发连接数时,性能很差 | 随着连接数的增加,性能基本没有变化 |
| 连接数 | 一般1024 | 无限制 | 无限制 |
| 内存拷贝 | 每次调用select拷贝 | 每次调用poll拷贝 | fd首次调用epoll_ctl拷贝,每次调用epoll_wait不拷贝 |
| 数据结构 | bitmap | 数组 | 红黑树 |
| 内在处理机制 | 线性轮询 | 线性轮询 | FD挂在红黑树,通过事件回调callback |
| 时间复杂度 | O(n) | O(n) | O(1) |
4) Redis的IO

